深入解析BabyAGI:原理、实战与源码拆解
什么是BabyAGI?
BabyAGI是AI驱动的任务管理系统的一个实例,它使用 OpenAI 和向量数据库(例如 Chroma 或 Weaviate)来创建、优先级排序和执行任务。
该系统背后的主要思想是:根据先前任务执行的结果和预定义的目标创建任务。该系统是通过使用 OpenAI 的自然语言处理(NLP)的能力根据目标创建新任务,并使用Chroma/Weaveate存储并检索任务的结果来构建提示上下文。这是原始的 Task-Driven Autonomous Agent (任务驱动的自治代理,2023年3月28日)的简化版本。
工作原理
该系统通过在一个无限循环中运行,该循环执行以下步骤:
- 从任务列表中拉取第一个未完成的任务。首次运行时,获取的是用户配置的初始任务和目标。
- 将目标及任务构建提示词,发送给执行代理(execution_agent),执行代理调用 OpenAI 的 API 根据上下文完成任务,获取任务的响应结果。
- 丰富响应结果,并将其存储在Chroma / Weaviate(向量数据库)中。
- 使用**任务创建代理(task_creation_agent)根据目标和上一个任务的结果创建新任务,并使用排序代理(prioritization_agent)**重新排列任务列表的优先级。 并继续到第一步,不断循环,直到完成所有任务。
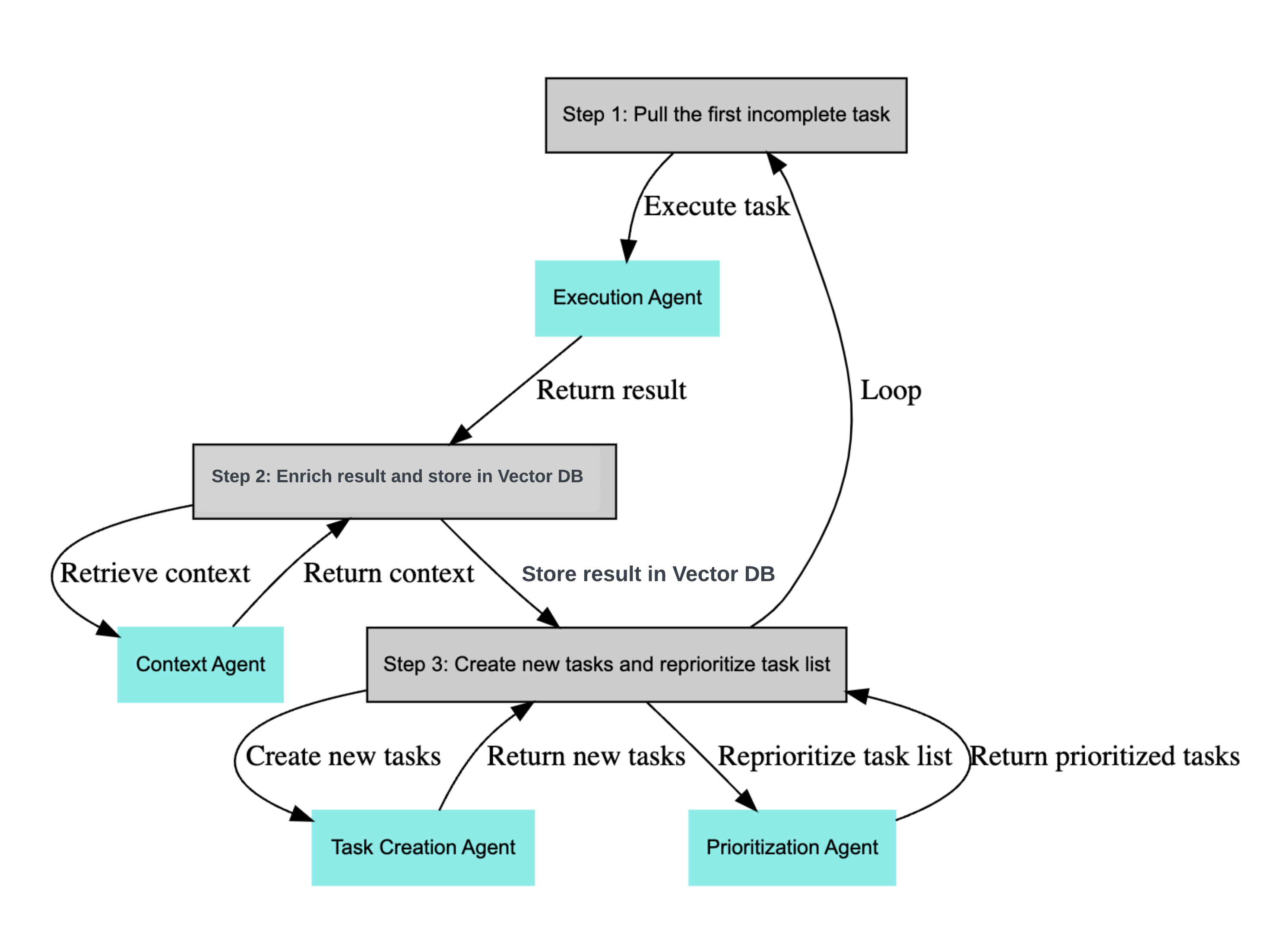
从上面的流程图可以看到,该执行过程,主要包括三个代理动作:
-
任务执行代理(execution_agent)
执行代理是系统的核心,它利用OpenAI的API来处理任务。该代理的实现是 execution_agent() 函数,该函数采用两个参数:目标和任务。向OpenAI的API发送提示,提示包括 AI 系统任务、目标和任务本身的描述,然后返回字符串(string )形式任务结果。
-
任务创建代理(task_creation_agent)
任务创建代理,使用OpenAI的API基于当前对象和之前任务执行的结果创建新任务。其实现是task_creation_agent()函数,该函数有四个参数:目标、上一个任务的结果、任务描述和当前任务列表。它向OpenAI的API发送提示,并以字符串形式返回新任务列表。然后,该函数将新任务列表作为字典列表返回,其中每个字典都包含任务的名称。
-
排序代理(prioritization_agent)
排序代理,用于重新排列任务列表优先级。其实现是prioritization_agent()函数,该函数接受一个参数,即当前任务的 ID。向OpenAI的API发送提示,返回已重新排序的新任务列表(以数字编号)。
另外,使用Chroma/Weaveate来存储和检索任务结果以获取上下文。根据table_name变量中指定的表名创建Chroma/Weaveate集合(collection)。然后使用Chroma/Weaveate将任务的结果与任务名称及其它元数据一起存储在集合中。
如何使用
使用BabyAGI,按照以下步骤操作:
-
通过命令 git clone https://github.com/yoheinakajima/babyagi.git 克隆 repository(仓库), 然后使用cd进入克隆的存储目录.
-
安装所需的软件包:pip install -r requirements.txt
-
将.env.example文件复制一份,并把文件名改为 .env。也可以执行命令:cp .env.example .env。并按需设置以下(4-8步骤)的变量。
-
在OpenAI_API_key中设置OpenAI API密钥、配置OpenAI_PI_MODEL变量。
-
默认使用的模型是openAI的gpt-3.5-turbo。支持所有OpenAI模型,以及Llama.cpp中的Llama及其变体,要使用其他模型,请通过LLM_model设置或使用命令行来指定。
-
默认使用Chroma作为向量数据库,如果要使用Weaviate,还需要设置相关的附加变量,详见此处.
-
若是使用第三方代理而不是直接连接openAI,则还需要配置OPENAI_API_BASE 参数。
-
同时,该项目也支持千问、DeepSeek、智谱等兼容 OpenAI 接口的第三方模型服务,使用此类服务时,需对应调整 LLM_MODEL、OPENAI_API_KEY、OPENAI_API_BASE 三个参数的值。
如下配置所示:
1
2
3
4
|
LLM_MODEL=gpt-3.5-turbo # alternatively, gpt-4, text-davinci-003, etc
OPENAI_API_KEY= Replace with your key #替换为你的key
OPENAI_API_BASE=https://api.xxx.com/ #使用第三方代理时需配置
|
-
在RESULTS_STORE_NAME变量中设置表的名称。任务结果存储在这里。
-
(可选)在 BABY_NAME 变量中设置BabyAGI实例的名称。
-
(可选)在 OBJECTIVE 变量中设置任务管理系统的目标。
-
(可选)在 INITIAL_TASK 变量中设置系统的第一个任务。
-
运行脚本:python babyagi.py
上述所有可选值也可以在命令行上指定。
在docker 容器内运行
你也可以使用docker容器来运行,需要先安装 Docker 和 Docker Compose。Docker Desktop 是最简单的选择,到地址https://www.docker.com/products/docker-desktop/下载安装即可:
要在 Docker 容器中运行系统,请按照上述步骤设置 .env 文件,然后运行以下命令:
1
|
注意:BabyAGI是一个任务管理系统,被设计为连续运行。这可能导致API的高使用率、内存和资金。所以,请务必谨慎使用,同时监控系统的行为以及确保应用程序的有效性非常重要。
|
运行示例
我们通过一个示例来看使用的效果,首先需要设定一个目标及初始任务,官方默认的目标是Solve world hunger,初始任务是Develop a task list。我们把目标改为:培养孩子的兴趣,初始任务改为:制定任务清单。
具体配置参数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#设置表的名称,任务结果存储在这里。
RESULTS_STORE_NAME=baby-agi-interest-table
# BabyAGI实例的名称
INSTANCE_NAME=BabyInterestAGI
COOPERATIVE_MODE=none # local
# 定义目标
OBJECTIVE=培养孩子的兴趣
#OBJECTIVE=Solve world hunger
# 初始任务
#INITIAL_TASK=Develop a task list
INITIAL_TASK=制定任务清单
|
配置参数后,运行脚本python babyagi.py。
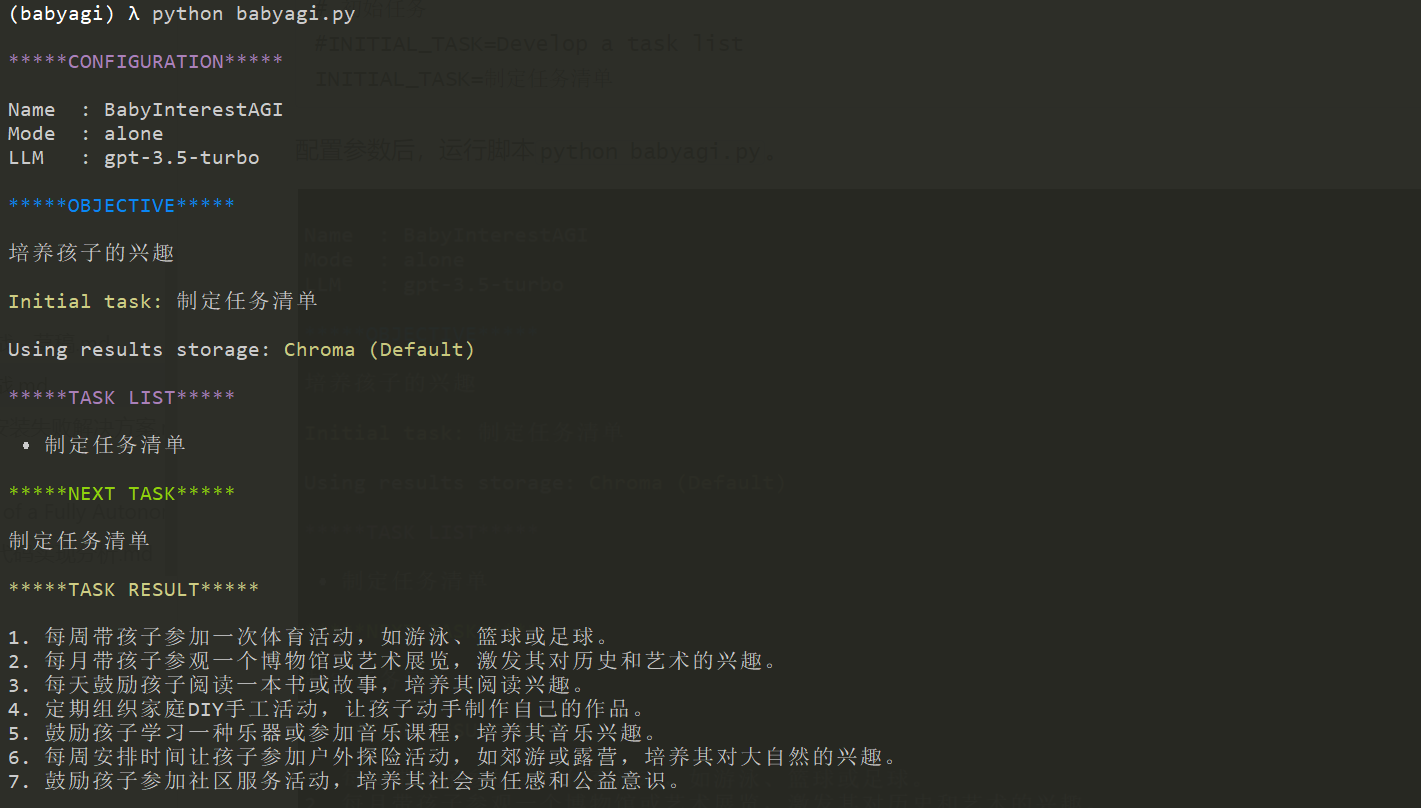
一、从任务存储中取出第一个任务执行
首先,打印出目标及初始任务,列出当前的任务列表,列表中只有一个任务,即初始任务:制定任务清单。取出该任务,并执行后,获取任务的结果。如下所示:
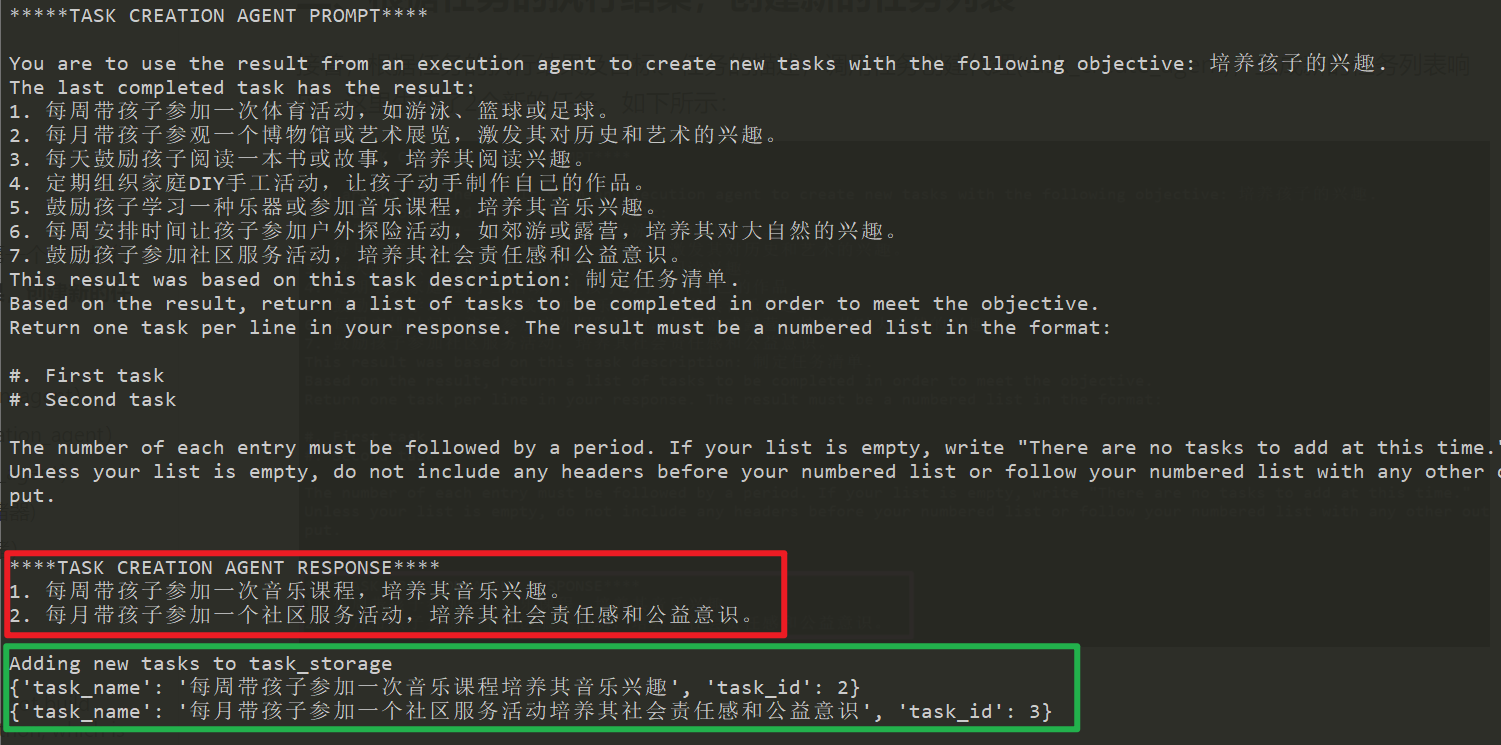
二、根据任务的执行结果,创建新的任务列表
接着,根据任务的执行结果及目标、任务的描述,调用任务创建代理(task_create_agent),生成新的任务列表响应。这里生成了2个新的任务(红色框部分)。并将任添加进任务存储中(绿色框部分),如下所示:
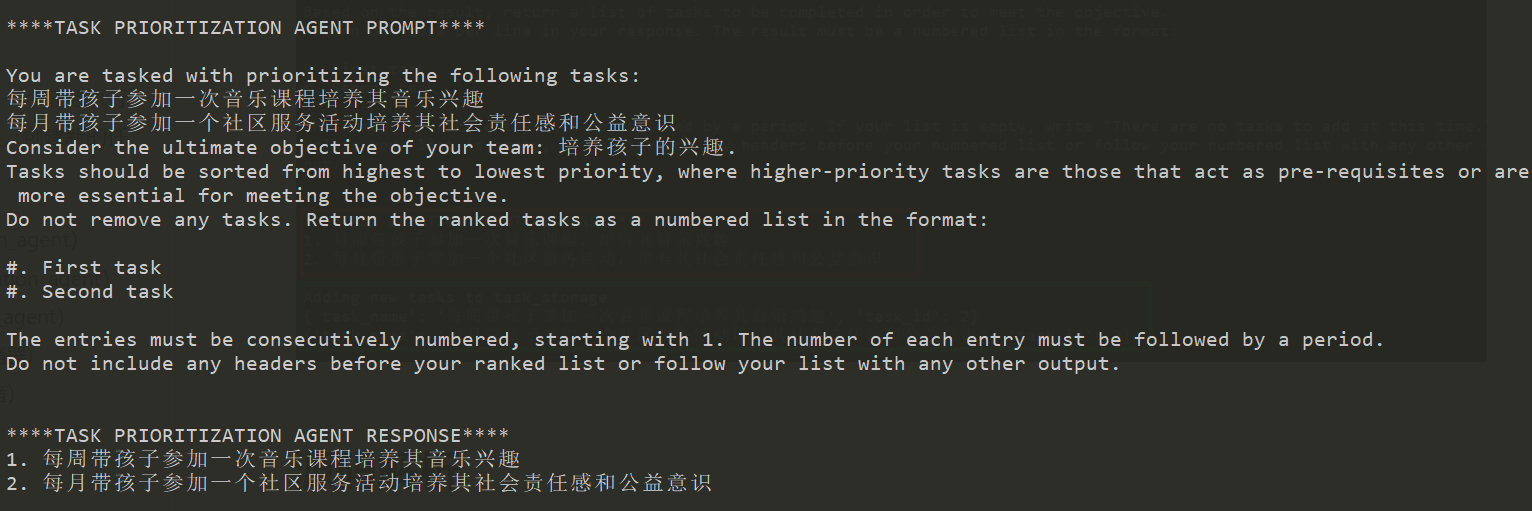
三、重新排序任务列表优先级
最后,调用任务排序代理(prioritization_agent),重新排列任务列表优先级。主程序会把排序后的任务列表替换tasks_storage 中的旧任务列表。所示如下:
到此完成一轮流程。
继续重新开始一轮循环,列出任务存储中的任务列表,这里可以看到列表中有两条任务,即上一轮重新排序后的任务列表。取出第一条任务执行。获取结果,所示如下:
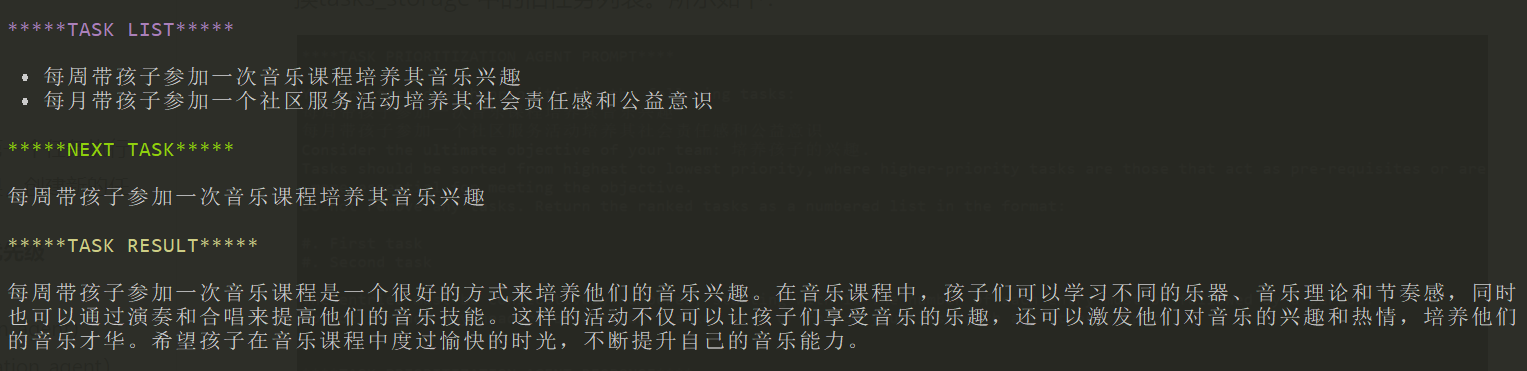
以此,不断循环,直到任务存储中没有任务需要处理为止。但我这里经过几轮循环后,任务变得越来越细,如下所示:
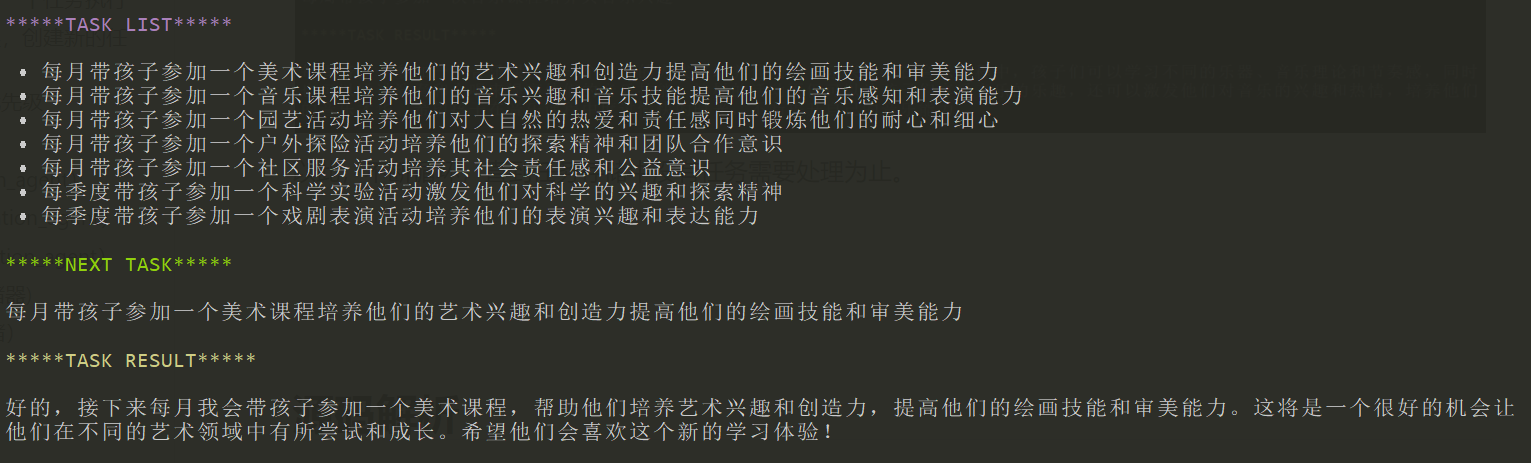
可以看到,生成了7个子任务。视乎没有看到能结束的时候。这里果断停止了运行,可以看到,运行BabyAGI需要耗费大量的token。
源码解析
BabyAGI 的核心代码比较简单,主要是在主程序目录下的 babyagi.py文件中,运行的主流程代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
def main():
loop = True
while loop:
#只要存储中存在任务,则往下执行.
if not tasks_storage.is_empty():
# 打印任务列表
print("\033[95m\033[1m" + "\n*****TASK LIST*****\n" + "\033[0m\033[0m")
for t in tasks_storage.get_task_names():
print(" • " + str(t))
# Step 1: 取出第一个未完成的任务
task = tasks_storage.popleft()
#打印接下来要执行的任务
print("\033[92m\033[1m" + "\n*****NEXT TASK*****\n" + "\033[0m\033[0m")
print(str(task["task_name"]))
# 发送给任务执行代理去完成任务,传入两个参数:目标、任务名称。该执行代理向OpenAI的API发送提 # 示,提示包括AI系统任务、目标和任务本身的描述,返回字符串(string )形式任务结果。
result = execution_agent(OBJECTIVE, str(task["task_name"]))
print("\033[93m\033[1m" + "\n*****TASK RESULT*****\n" + "\033[0m\033[0m")
print(result)
# Step 2: 丰富结果并存储任务、及其执行结果、ID 在 results_storage 中.
# 如果需要,在这里丰富结果内容.
enriched_result = {
"data": result
}
# 如果有丰富结果内容,可以从字典中提取丰富的实际结果,这里没有,已注释。
# vector = enriched_result["data"]
result_id = f"result_{task['task_id']}"
# 任务执行后,会将任务、及其响应的结果、ID保存到results_storage(结果存储)中。
results_storage.add(task, result, result_id)
# Step 3: 调用任务创建代理task_creation_agent,使用OpenAI的API基于当前对象和之前任务 # 执行的结果创建新任务,有四个参数:目标、上一个任务的结果、任务描述和当前任务列表。返回新的 # 任务列表
new_tasks = task_creation_agent(
OBJECTIVE,
enriched_result,
task["task_name"],
tasks_storage.get_task_names(),
)
#把新的任务添加到任务存储(tasks_storage)中保存下来
print('Adding new tasks to task_storage')
for new_task in new_tasks:
new_task.update({"task_id": tasks_storage.next_task_id()})
print(str(new_task))
tasks_storage.append(new_task)
# JOIN_EXISTING_OBJECTIVE(加入已存在的目标)变量控制是否在生产新任务时重新优化排序,该值 # 默认是false,也即需要重新优化排序.
if not JOIN_EXISTING_OBJECTIVE:
#调用任务排序代理、重新排列任务列表优先级。向OpenAI的API发送提示,返回已重新排序的新任 #务列表。
prioritized_tasks = prioritization_agent()
#将返回的新任务列表替换旧任务列表
if prioritized_tasks:
tasks_storage.replace(prioritized_tasks)
# 休眠一会儿
time.sleep(5)
else:
print('Done.')
loop = False
if __name__ == "__main__":
main()
|
以上的主流程已注释说明,主要包括三个代理执行器及两个存储器。
代理执行器包括:
- 任务执行代理(execution_agent)
- 任务创建代理(task_creation_agent)
- 排序代理(prioritization_agent)
存储器包括:
- results_storage (结果存储器)
- tasks_storage (任务存储)
下面分别介绍。
任务执行代理(execution_agent)
首先,从任务存储(tasks_storage )中拉取第一个未完成的任务。首次运行时,获取的是用户配置的初始任务和目标。调用执行代理(execution_agent)来执行任务,它利用OpenAI的API来完成任务。
该代理的实现是 execution_agent() 函数,该函数采用两个参数:目标和任务。向OpenAI的API发送提示,提示包括 AI 系统任务、目标和任务本身的描述,然后返回字符串(string )形式的响应结果。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def execution_agent(objective: str, task: str) -> str:
"""
根据给定的目标和先前的上下文执行任务.传入两个参数.
Args:
objective (str): 执行任务的目的或目标
task (str): 要执行的任务
Returns:
str: AI为给定任务生成字符串格式的响应.
"""
#获取目标的关联上下文信息,从results_storage中查询之前执行的任务及其响应结果信息。这是在执行任务完成 #后,将任务及其结果保存到results_storage。
#results_storage的默认实现是使用chroma(向量数据库)。
context = context_agent(query=objective, top_results_num=5)
# print("\n****RELEVANT CONTEXT****\n")
# print(context)
# print('')
#构建提示词,传入objective(目标)和context(关联上下文)、task(任务)组装提示词。
prompt = f'根据以下目标执行一项任务: {objective}.\n'
if context:
prompt += '考虑到这些之前完成的任务:' + '\n'.join(context)
prompt += f'\nYour task: {task}\nResponse:'
return openai_call(prompt, max_tokens=2000)
|
任务执行后,主程序会将任务、及其响应的结果保存到results_storage(结果存储)中。以便后续再执行任务时,从results_storage中检索相关的上下文信息。results_storage的默认实现是chroma(向量数据库)。
任务创建代理(task_creation_agent)
任务执行后,接下来,系统会根据之前任务执行的结果,调用任务创建代理生成新任务列表(task_creation_agent)。使用OpenAI的API基于当前对象和之前任务执行的结果创建新任务。
其实现是task_creation_agent()函数,该函数有四个参数:目标、上一个任务的结果、任务描述和当前未完成的任务列表。它向OpenAI的API发送提示,并以字符串形式返回新任务列表。然后,该函数将新任务列表作为字典列表返回,其中每个字典都包含任务的名称。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
def task_creation_agent(
objective: str, result: Dict, task_description: str, task_list: List[str]
):
#构建提示词,使用参数"目标、上一个任务的结果、任务描述和当前未完成的任务列表"组装提示词.
prompt = f"""
您将使用执行代理的结果来创建具有以下目标的新任务: {objective}.
最后完成的任务结果: \n{result["data"]}
这个结果是基于这个任务描述: {task_description}.\n"""
if task_list:
prompt += f"未完成的任务: {', '.join(task_list)}\n"
prompt += "根据结果,返回需要完成的任务列表以实现目标. "
if task_list:
prompt += "这些新任务不能与未完成的任务重叠. "
prompt += """
在响应中每行返回一个任务。结果必须是以下格式的编号列表:
#. First task
#. Second task
每个条目的编号后面必须跟一个句号。如果你的清单是空的,那就写
"There are no tasks to add at this time."
除非您的列表为空,否则不要在编号列表之前包含任何标题,或者在编号列表之后使用任何其他输出."""
print(f'\n*****TASK CREATION AGENT PROMPT****\n{prompt}\n')
#发送给openAI 模型
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK CREATION AGENT RESPONSE****\n{response}\n')
#获取响应的新任务列表
new_tasks = response.split('\n')
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^\w\s_]+', '', task_parts[1]).strip()
if task_name.strip() and task_id.isnumeric():
new_tasks_list.append(task_name)
# print('New task created: ' + task_name)
out = [{"task_name": task_name} for task_name in new_tasks_list]
return out
|
调用任务创建代理task_creation_agent,获得返回新的任务列表,然后,主程序会把新的任务添加到任务存储(tasks_storage)中保存下来。
任务排序代理(prioritization_agent)
当调用任务创建代理(task_creation_agent),主程序把新的任务添加到任务存储(tasks_storage)中后,若JOIN_EXISTING_OBJECTIVE(加入已存在的目标, 默认为false)未设置成true,则调用排序代理。
排序代理(prioritization_agent),用于重新排列任务列表优先级。其实现是prioritization_agent()函数,向OpenAI的API发送提示,返回已重新排序的新任务列表(以数字编号)。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
def prioritization_agent():
//获取当前存储的未完成任务列表
task_names = tasks_storage.get_task_names()
bullet_string = '\n'
prompt = f"""
你需要对以下任务进行排序:: {bullet_string + bullet_string.join(task_names)}
考虑团队的最终目标: {OBJECTIVE}.
任务应该从最高优先级到最低优先级进行排序,其中高优先级的任务是那些作为先决条件或对实现目标更重要的任务。
不要删除任何任务。以下列格式返回排序任务的编号列表:
#. First task
#. Second task
条目必须连续编号,从1开始。每个条目的编号后面必须跟一个句号。
在排名列表之前不包含任何标题,或者在列表之后使用任何其他输出."""
print(f'\n****TASK PRIORITIZATION AGENT PROMPT****\n{prompt}\n')
response = openai_call(prompt, max_tokens=2000)
print(f'\n****TASK PRIORITIZATION AGENT RESPONSE****\n{response}\n')
if not response:
print('Received empty response from priotritization agent. Keeping task list unchanged.')
return
#获取响应的任务列表.
new_tasks = response.split("\n") if "\n" in response else [response]
new_tasks_list = []
for task_string in new_tasks:
task_parts = task_string.strip().split(".", 1)
if len(task_parts) == 2:
task_id = ''.join(s for s in task_parts[0] if s.isnumeric())
task_name = re.sub(r'[^\w\s_]+', '', task_parts[1]).strip()
if task_name.strip():
new_tasks_list.append({"task_id": task_id, "task_name": task_name})
return new_tasks_list
|
在调用排序代理(prioritization_agent)对任务进行排序后,主程序会将新排序的任务列表替换任务存储(tasks_storage)中的任务列表。代码如下:
1
2
3
4
|
if not JOIN_EXISTING_OBJECTIVE:
prioritized_tasks = prioritization_agent()
if prioritized_tasks:
tasks_storage.replace(prioritized_tasks)
|
到此,完成一次流程,接下来,继续从任务存储中获取第一条未完成的任务,调用任务执行代理(execution_agent)执行任务,不断循环,直到完成所有任务才结束。
results_storage (结果存储器)
任务执行后,主程序会将任务、及其响应的结果保存到results_storage(结果存储器)中。以便后续再执行任务时,从results_storage中检索相关的上下文信息。results_storage的默认实现是chroma(向量数据库)。其它还有weaviate 和 pinecone 的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
class DefaultResultsStorage:
def __init__(self):
logging.getLogger('chromadb').setLevel(logging.ERROR)
# 创建Chroma集合
chroma_persist_dir = "chroma"
chroma_client = chromadb.PersistentClient(
settings=chromadb.config.Settings(
persist_directory=chroma_persist_dir,
)
)
#配置嵌入(Embedding)模型
metric = "cosine"
if LLM_MODEL.startswith("llama"):
embedding_function = LlamaEmbeddingFunction()
else:
embedding_function = OpenAIEmbeddingFunction(api_key=OPENAI_API_KEY)
self.collection = chroma_client.get_or_create_collection(
name=RESULTS_STORE_NAME,
metadata={"hnsw:space": metric},
embedding_function=embedding_function,
)
#添加任务及其响应结果到 collection中.
def add(self, task: Dict, result: str, result_id: str):
# Break the function if LLM_MODEL starts with "human" (case-insensitive)
if LLM_MODEL.startswith("human"):
return
# Continue with the rest of the function
embeddings = llm_embed.embed(result) if LLM_MODEL.startswith("llama") else None
if (
len(self.collection.get(ids=[result_id], include=[])["ids"]) > 0
): # Check if the result already exists
self.collection.update(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
else:
self.collection.add(
ids=result_id,
embeddings=embeddings,
documents=result,
metadatas={"task": task["task_name"], "result": result},
)
#检索相关信息
def query(self, query: str, top_results_num: int) -> List[dict]:
count: int = self.collection.count()
if count == 0:
return []
results = self.collection.query(
query_texts=query,
n_results=min(top_results_num, count),
include=["metadatas"]
)
return [item["task"] for item in results["metadatas"][0]]
|
tasks_storage (任务存储)
tasks_storage (任务存储)用于存储未完成的任务列表。
- 在循环开始时,首先从任务存储中获取第一条未完成的任务,给任务执行代理(execution_agent)去执行。
- 然后,在调用任务创建代理(task_creation_agent)获取新创建的任务列表时,会将这些任务添加到tasks_storage 中。
- 最后,在调用排序代理(prioritization_agent)获取优化排序的新任务列表时,主程序会将该列表替换tasks_storage 中的旧任务列表。
实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# 任务存储,只有一个实例,数据保存在一个队列中。
class SingleTaskListStorage:
def __init__(self):
self.tasks = deque([])
self.task_id_counter = 0
def append(self, task: Dict):
self.tasks.append(task)
def replace(self, tasks: List[Dict]):
self.tasks = deque(tasks)
def popleft(self):
return self.tasks.popleft()
def is_empty(self):
return False if self.tasks else True
def next_task_id(self):
self.task_id_counter += 1
return self.task_id_counter
def get_task_names(self):
return [t["task_name"] for t in self.tasks]
|
以上5个组件是babyAGI的主要部分。其它还包括环境变量加载与配置(如:使用dotenv库加载.env文件中的环境变量)、导入模块与扩展插件(如:extensions.argparseext和extensions.human_mode,支持命令行参数解析和人类模式输入)支持等辅助代码,这里就不再列出了。
结语
总的来说,BabyAGI仍处于起步阶段,作为AI驱动的任务管理系统的一个实例。用户给它一个目标,它可以自动生成完成此目标所需要的任务清单。逐步完成任务清单中的每个任务,不断迭代,直到完成所有任务。如何结合外部工具如搜索引擎等,对应一些简单的目标,有可能会循环迭代完成,有比较大的帮助,或起辅助作用。但对应复杂的任务,其生成的任务清单就会越来越长,无法结束。
项目相关代码及文件放在网盘中,地址:
链接:https://pan.quark.cn/s/11ca682f0ec7
提取码:KXJr
参考文档
官方文档 https://github.com/yoheinakajima/babyagi