深入解析AgentGPT:原理、实战与源码拆解
介绍
AgentGPT是一个自主AI代理平台,它使用户能够在浏览器中创建和部署可定制的自主AI代理。只需要指定一个目标,然后观看它自动开始一段激动人心的旅程,以完成指定的任务。AgentGPT通过调用大型语言模型(如GPT-4)来实现目标,旨在在无需人类干预的情况下理解目标、制定策略并交付结果。
AgentGPT的基本思路是:给它一个任意目标,AgentGPT首先会对目标进行分解成一系列子任务,然后对每一项子任务进行分析思考、并按需要使用外部工具来执行任务,然后完成所有子任务。并从子任务的执行结果来学习总结,最终完成用户的目标。而且这一系列过程是自动完成的。可以把它看成是 AutoGPT与 babyAGI结合的增强版本,而且还提供了网页端,用户会话管理及历史交互的数据库存储。
安装
本节指导您在本地安装 AgentGPT。有两种安装方式:docker安装及命令行(非docker)安装。官方建议使用 Docker 进行安装,因为Docker 简化了安装过程,所有的依赖项都已处理好,使得安装过程更加简单,出错的可能性更小。
由于我们主要是在学习,为了更好的了解项目结构、配置、及其运行过程,我们这里推荐使用命令行的方式来运行。
前提条件
在开始之前,需要安装了以下软件:
- Git:是一个开源的分布式版本控制系统,用于从github中下载项目代码。
- Node.js:一个开源、跨平台的 JavaScript 运行时环境,运行前端时需要。
- OpenAI API key :由于国内无法直连openAI的官方接口,解决方法是可以使用第三方提供的服务,或使用azure openAl 的接口服务。推荐使用azure openAI。
Docker 方式安装
除了上述的先决条件外,还需要安装Docker。按照以下步骤进行Docker的安装:
Docker方式安装步骤如下:
-
打开Terminal
-
clone 存储库并进入目录 ,通过运行以下命令来克隆存储库并进入目录:
Mac/Linux 用户
1
2
3
|
git clone https://github.com/reworkd/AgentGPT.git
cd AgentGPT
./setup.sh
|
Windows 用户
1
2
3
|
git clone https://github.com/reworkd/AgentGPT.git
cd AgentGPT
./setup.bat
|
-
按照运行setup.bat脚本中的设置向导,添加openAI API密钥。
一旦所有服务都开始运行,在web浏览器上访问http://localhost:3000。
命令行安装(非docker方式)
一、下载源码及运行setub.bat脚本
非Docker方式安装,同样需要下载源代码,并运行setup.sh脚本(window环境下运行setup.bat脚本)配置ENV文件,同时需要更新Prisma的配置指向本地SQLite实例。
1
|
Prisma是一个开源的数据库工具和对象关系映射(ORM)框架,通过提供丰富的功能和强大的集成支持,简化了开发人员与数据库的交互过程,提高了开发效率和代码质量。Prisma与TypeScript紧密集成,确保了开发过程中的类型安全性。它支持多种数据库,包括MySQL、PostgreSQL、MongoDB等,并且支持多种编程语言,如JavaScript、TypeScript、Go等。Prisma还提供了高效、类型安全的数据访问方式,使开发者能够获得有关数据库事件的通知。
|
1
2
3
|
git clone https://github.com/reworkd/AgentGPT.git
cd AgentGPT
./setup.sh
|
运行setub.bat脚本会引导你设置一些必要的参数,如openAI API密钥。 如果你使用的是第三方连接openAI或 azure 提供的openAI 服务时,可以先不设置,直接回车。
AgentGPT 代码包括 platform(后端工程)和 next(前端工程)两个部分。
脚本运行完成后,会在 platform(后端工程)目录及 next(前端工程)目录下分别创建.env文件,然后在该文件中设置OPENAI_API_KEY及数据库连接配置。使用第三方连接openAI或 azure 提供的openAI 服务时,还需要配置OPENAI_API_BASE。
二、参数配置
在后端工程目platform找到名为.env.template的文件,复制并将其命名为.env
具体配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#部署环境,默认development(开发模式),该模式使用简化的身份验证机制,以便于测试和调试。这种方式不安全,
#不应在生产环境中使用。
NODE_ENV=development
NEXT_PUBLIC_VERCEL_ENV=${NODE_ENV}
...//省略部分默认配置
#使用第三方的OAuth身份验证登录时配置 (在非development模式下有效):
GOOGLE_CLIENT_ID=***
GOOGLE_CLIENT_SECRET=***
GITHUB_CLIENT_ID=***
GITHUB_CLIENT_SECRET=***
DISCORD_CLIENT_SECRET=***
DISCORD_CLIENT_ID=***
# Backend:
REWORKD_PLATFORM_ENVIRONMENT=${NODE_ENV}
REWORKD_PLATFORM_FF_MOCK_MODE_ENABLED=false
REWORKD_PLATFORM_MAX_LOOPS=${NEXT_PUBLIC_MAX_LOOPS}
#重要配置OPENAI_API_KEY、REWORKD_PLATFORM_OPENAI_API_BASE
#支持兼容 OpenAI 接口的模型服务(如:千问、DeepSeek、智谱等),使用此类服务时,需对应调整 #`REWORKD_PLATFORM_OPENAI_API_KEY`、`REWORKD_PLATFORM_OPENAI_API_BASE` 参数的值。
REWORKD_PLATFORM_OPENAI_API_KEY="替换为你自己的api key"
REWORKD_PLATFORM_FRONTEND_URL=http://localhost:3000
REWORKD_PLATFORM_RELOAD=true
#若使用第三方连接openAI、azure提供的openAI服务、兼容 OpenAI 接口的模型服务,配置请求的端口
REWORKD_PLATFORM_OPENAI_API_BASE=https://api.chatanywhere.tech
REWORKD_PLATFORM_SERP_API_KEY=""
REWORKD_PLATFORM_REPLICATE_API_KEY=""
# 后端连接数据库配置 (Backend):
REWORKD_PLATFORM_DATABASE_USER=root #连接数据库的用户名
REWORKD_PLATFORM_DATABASE_PASSWORD=修改为你自己的数据库密钥 #连接数据库的密码
REWORKD_PLATFORM_DATABASE_HOST=localhost #连接数据库的IP地址
REWORKD_PLATFORM_DATABASE_PORT=3306 #连接数据库的IP端口
REWORKD_PLATFORM_DATABASE_NAME=reworkd_platform #连接数据库名称
REWORKD_PLATFORM_DATABASE_URL=mysql://${REWORKD_PLATFORM_DATABASE_USER}:${REWORKD_PLATFORM_DATABASE_PASSWORD}@${REWORKD_PLATFORM_DATABASE_HOST}:${REWORKD_PLATFORM_DATABASE_PORT}/${REWORKD_PLATFORM_DATABASE_NAME}
|
修改next/.env 文件,具体配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#部署环境,默认development(开发模式),该模式使用简化的身份验证机制,以便于测试和调试。这种方式不安全,
#不应在生产环境中使用。
NODE_ENV=development
NEXT_PUBLIC_VERCEL_ENV=${NODE_ENV}
# NextJS 与后端交互的URL:
NEXT_PUBLIC_BACKEND_URL=http://localhost:8000
NEXT_PUBLIC_MAX_LOOPS=100
# Next Auth config:
NEXTAUTH_SECRET=Ak+3iVAMOMLeLX2ahh9ZyAUIeoMs2YAnyNyHR9VKhwk=
NEXTAUTH_URL=http://localhost:3000
#使用第三方的OAuth身份验证登录时配置 (在非development模式下有效):
GOOGLE_CLIENT_ID=***
GOOGLE_CLIENT_SECRET=***
GITHUB_CLIENT_ID=***
GITHUB_CLIENT_SECRET=***
DISCORD_CLIENT_SECRET=***
DISCORD_CLIENT_ID=***
# 前端连接数据库配置 (Frontend):
DATABASE_USER=root
DATABASE_PASSWORD=修改为你自己的数据库密钥
DATABASE_HOST=localhost
DATABASE_PORT=3306
DATABASE_NAME=reworkd_platform
DATABASE_URL=mysql://${DATABASE_USER}:${DATABASE_PASSWORD}@${DATABASE_HOST}:${DATABASE_PORT}/${DATABASE_NAME}
|
三、数据库表结构初始化
AgentGPT使用数据库来持久化数据,如保存用户的注册信息及自定义Agent的历史交互等信息。
由于在官方下载的源文件中,找到的相关数据库初始化文件是\db\setup.sql ,但在该文件中,只有创建数据库的执行语句,并没有数据库表结构初始化的执行语句。所以我这里参照源代码整理了一份,在mysql数据库中,按setup.sql中的语句,创建好数据库reworkd_platform后,再执行以下语句创建表结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
-- ----------------------------
-- Table structure for agent
-- ----------------------------
DROP TABLE IF EXISTS `agent`;
CREATE TABLE `agent` (
`id` varchar(255) NOT NULL,
`userId` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`goal` varchar(255) DEFAULT NULL,
`deleteDate` datetime DEFAULT NULL,
`createDate` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for agent_run
-- ----------------------------
DROP TABLE IF EXISTS `agent_run`;
CREATE TABLE `agent_run` (
`id` varchar(255) NOT NULL,
`user_id` varchar(255) DEFAULT NULL,
`goal` varchar(500) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for agent_task
-- ----------------------------
DROP TABLE IF EXISTS `agent_task`;
CREATE TABLE `agent_task` (
`id` varchar(255) NOT NULL,
`run_id` varchar(255) DEFAULT NULL,
`type` varchar(255) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for agenttask
-- ----------------------------
DROP TABLE IF EXISTS `agenttask`;
CREATE TABLE `agenttask` (
`id` varchar(255) NOT NULL,
`agentId` varchar(255) DEFAULT NULL,
`type` varchar(100) DEFAULT NULL,
`status` varchar(255) DEFAULT NULL,
`value` text CHARACTER SET utf8mb4,
`info` text CHARACTER SET utf8mb4,
`sort` int(11) DEFAULT NULL,
`createDate` datetime DEFAULT NULL,
`deleteDate` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for oauth_credentials
-- ----------------------------
DROP TABLE IF EXISTS `oauth_credentials`;
CREATE TABLE `oauth_credentials` (
`id` varchar(100) NOT NULL,
`user_id` varchar(255) DEFAULT NULL,
`organization_id` varchar(255) DEFAULT NULL,
`provider` varchar(255) DEFAULT NULL,
`state` varchar(255) DEFAULT NULL,
`redirect_uri` varchar(255) DEFAULT NULL,
`token_type` varchar(255) DEFAULT NULL,
`access_token_enc` varchar(255) DEFAULT NULL,
`access_token_expiration` varchar(255) DEFAULT NULL,
`refresh_token_enc` varchar(255) DEFAULT NULL,
`scope` varchar(255) NOT NULL,
`create_date` datetime DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
`delete_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for organization
-- ----------------------------
DROP TABLE IF EXISTS `organization`;
CREATE TABLE `organization` (
`id` varchar(255) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`created_by` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for organization_user
-- ----------------------------
DROP TABLE IF EXISTS `organization_user`;
CREATE TABLE `organization_user` (
`id` varchar(255) NOT NULL,
`user_id` varchar(255) DEFAULT NULL,
`organization_id` varchar(255) DEFAULT NULL,
`role` varchar(255) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
`delete_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for session
-- ----------------------------
DROP TABLE IF EXISTS `session`;
CREATE TABLE `session` (
`id` varchar(255) NOT NULL,
`sessionToken` varchar(255) DEFAULT NULL,
`userId` varchar(255) DEFAULT NULL,
`expires` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` varchar(100) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`emailVerified` varchar(10) DEFAULT NULL,
`image` varchar(255) DEFAULT NULL,
`super_admin` tinyint(4) DEFAULT NULL,
`createDate` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
四、运行项目
配置好参数及创建了库表结构之后,运行以下命令来配置Next.js项目:
运行前端项目,cd 到下载根目录的next文件夹下,执行以下命令:
1
2
3
4
|
// Frontend
cd ./next
npm install
npm run dev
|
打开另一个窗口中,运行以下命令来启动后端:
1
2
3
4
|
// 确保您处于项目的根目标
cd ./platform
poetry install
poetry run python -m reworkd_platform
|
所有服务启动后,您可以在浏览器输入 http://localhost:3000 即可访问。
运行成功,会出现如下界面:
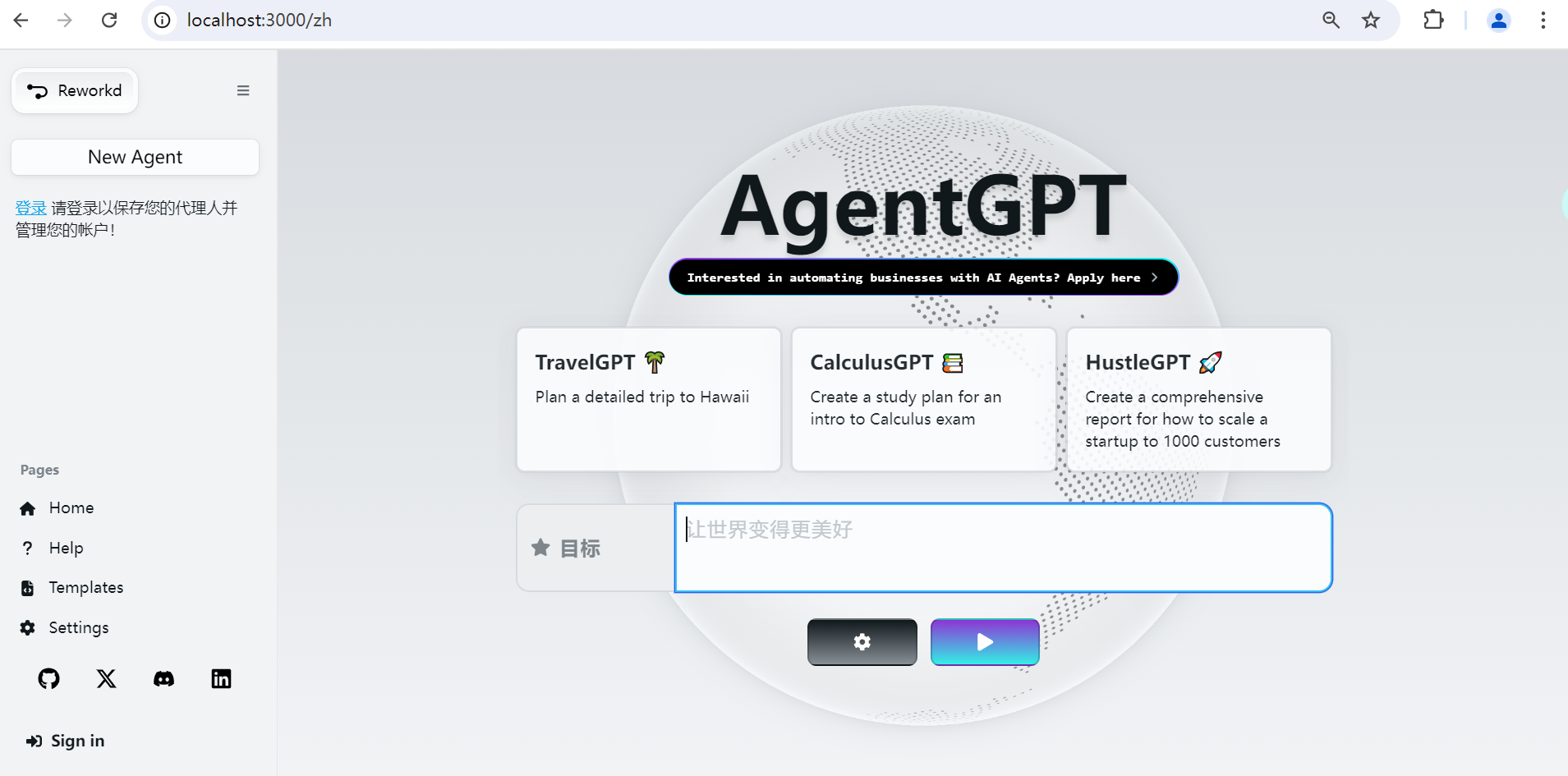
使用示例
登录
运行成功后,首先需要登录后才能使用,点击左下角的Sign in 链接,弹出对话框如下所示:
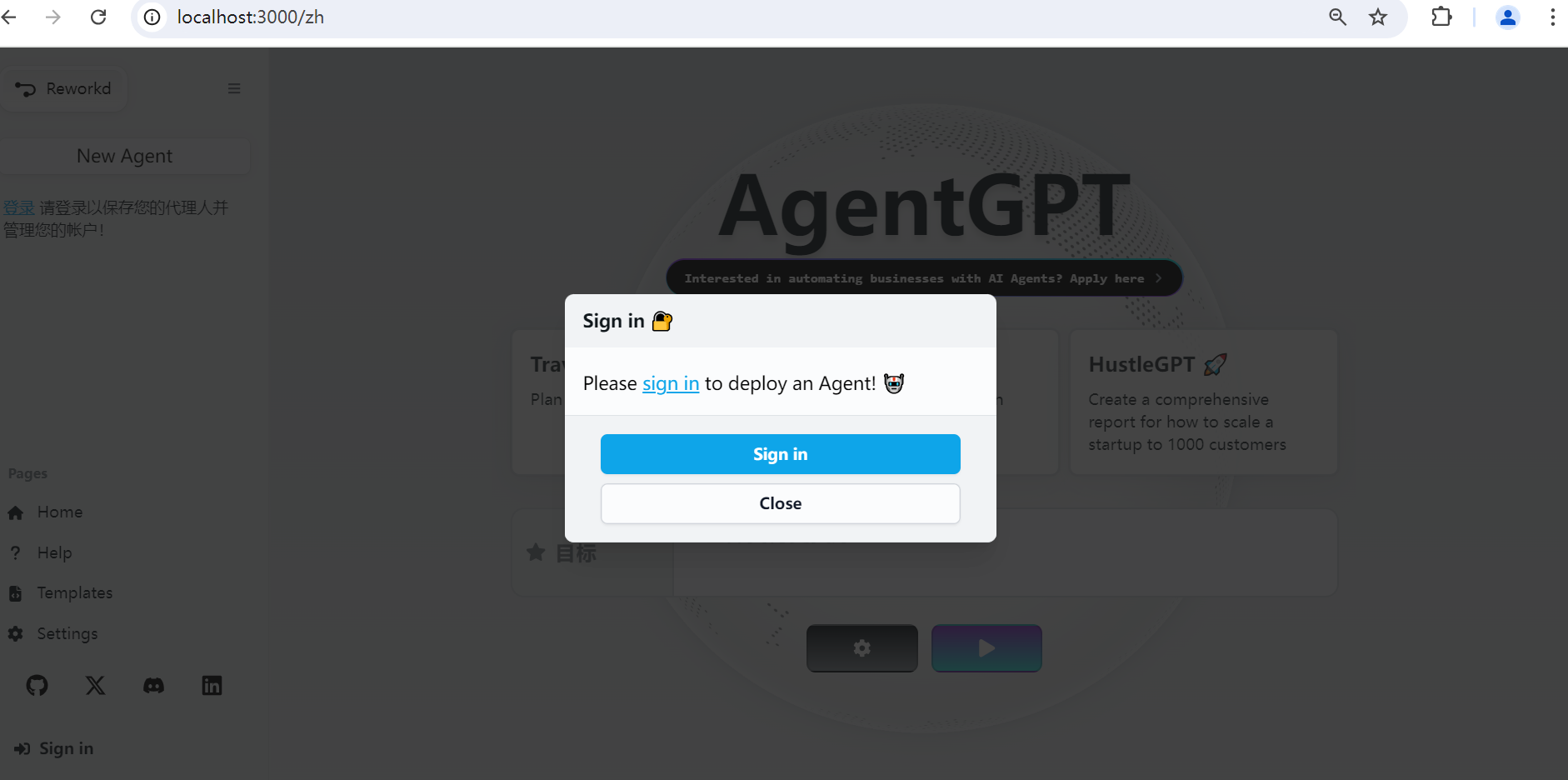
点击Sign in 按钮,弹出登录界面,如下所示:
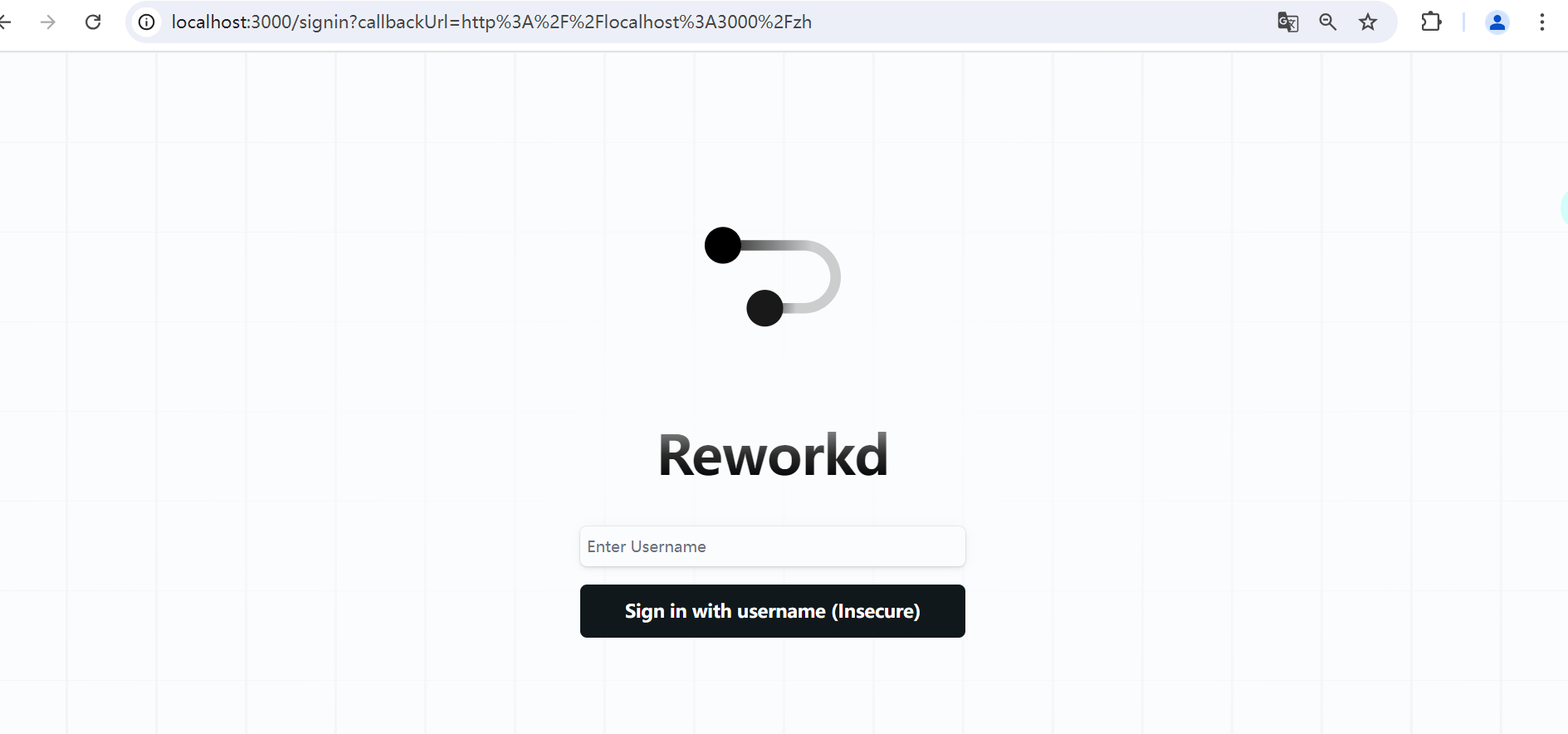
由于我们之前配置的是开发模式NODE_ENV=development(.env文件中),该模式简化了身份验证机制,只需要输入用户名即可,便于测试和调试。如果在生产环境中,需要修改为production。
输入用户名,即可登录,登录后左下角会显示用户名,左边菜单显示之前创建的Agent列表。如下图所示:
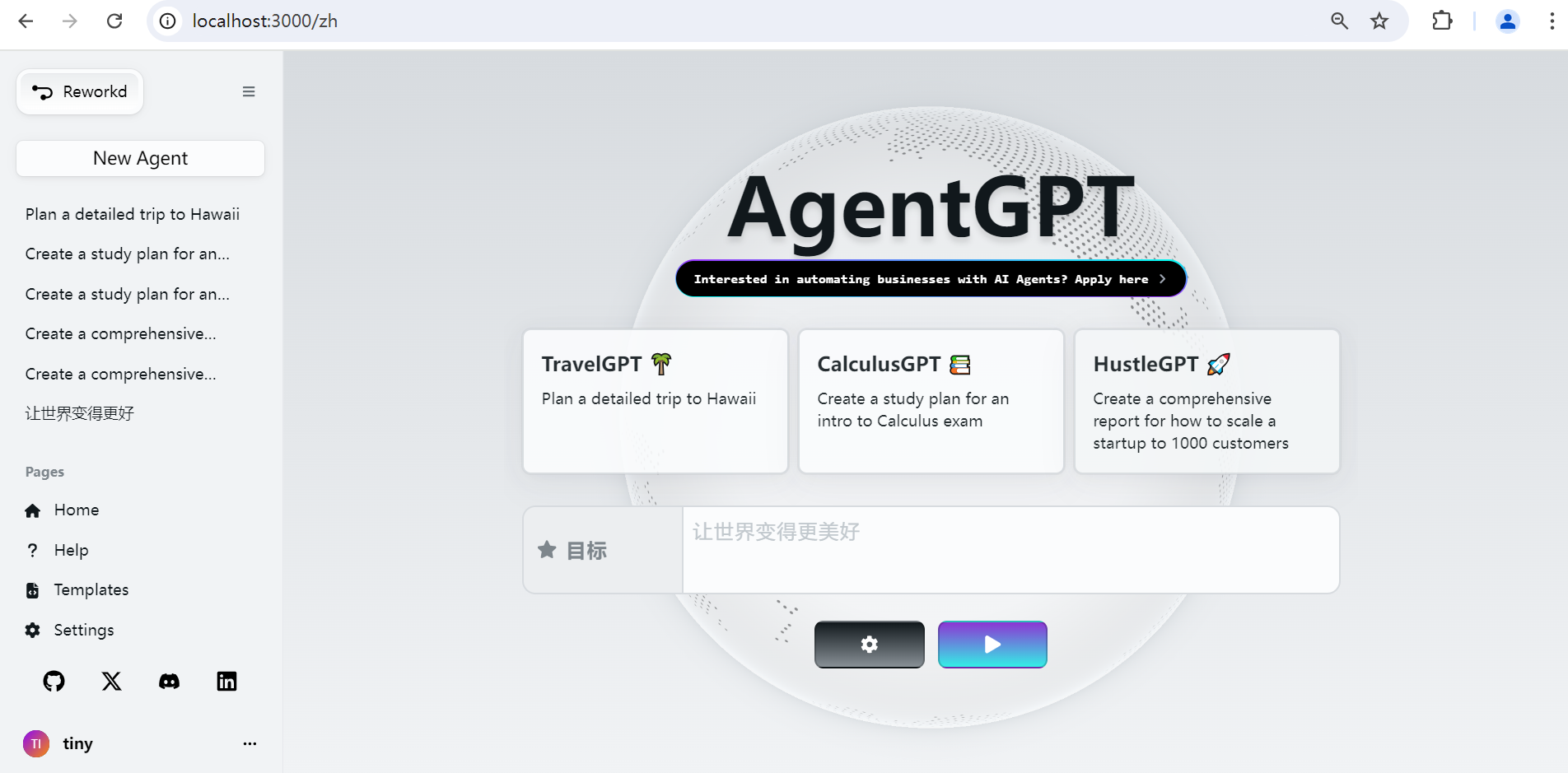
输入目标
agentGPT预先配置了三个Agent(TravelGPT、CalculusGPT、HustleGPT),您可以点击其中一个进行运行,也可以在下面的目标框中输入你要实现的目标,然后点击下面的运行 按钮开始运行。
按钮开始运行。
作为测试,我这里点击已配置的HustleGPT Agent,实现的目标是“Create a comprehensive report for how to scale a startup to 1000 customers “ ,翻译为中文为“编写一份详尽的报告,介绍如何将初创企业扩大到拥有1000名客户” 。接下来,我们就看着AengtGPT自动的为我们完成任务了。
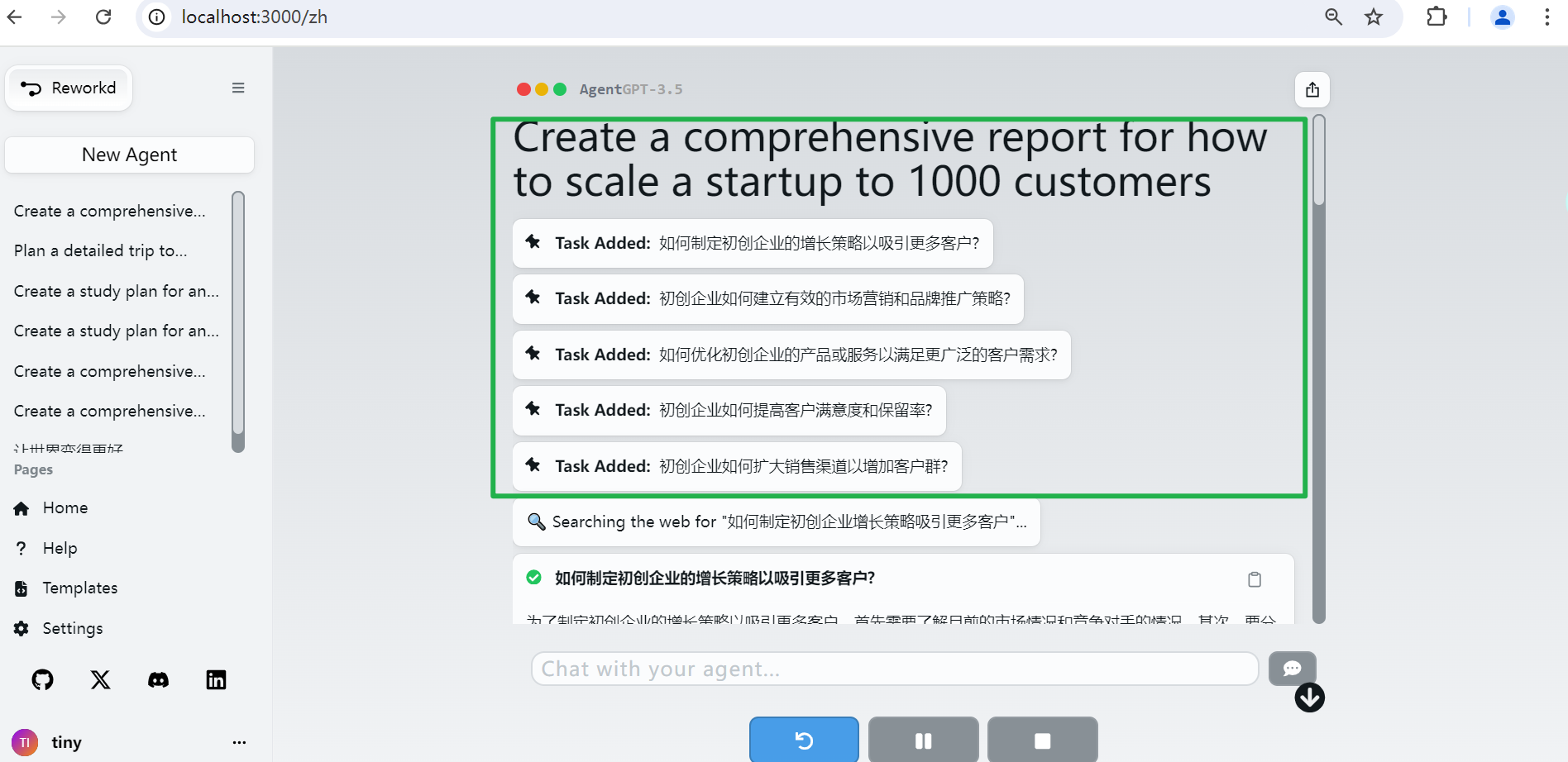
目标分解
AgentGPT 首先会对目标进行分解,生成一系列的子任务,这里生成了5个子任务,如下所示:
执行子任务
接着,AgentGPT会自动的依次完成每一个子任务, 在完成任务过程中,首先会对任务进行分析决策,返回要如何处理的方案,如是否需要调用工具搜索外部数据或执行代码等等。然后根据处理方案进行执行以完成任务。
如:这里处理“如何制定初创企业整长策略吸引更多客户”子任务时,对该任务分析决策的结果是,先进行web搜索,根据搜索的结果生成总结。如下所示:
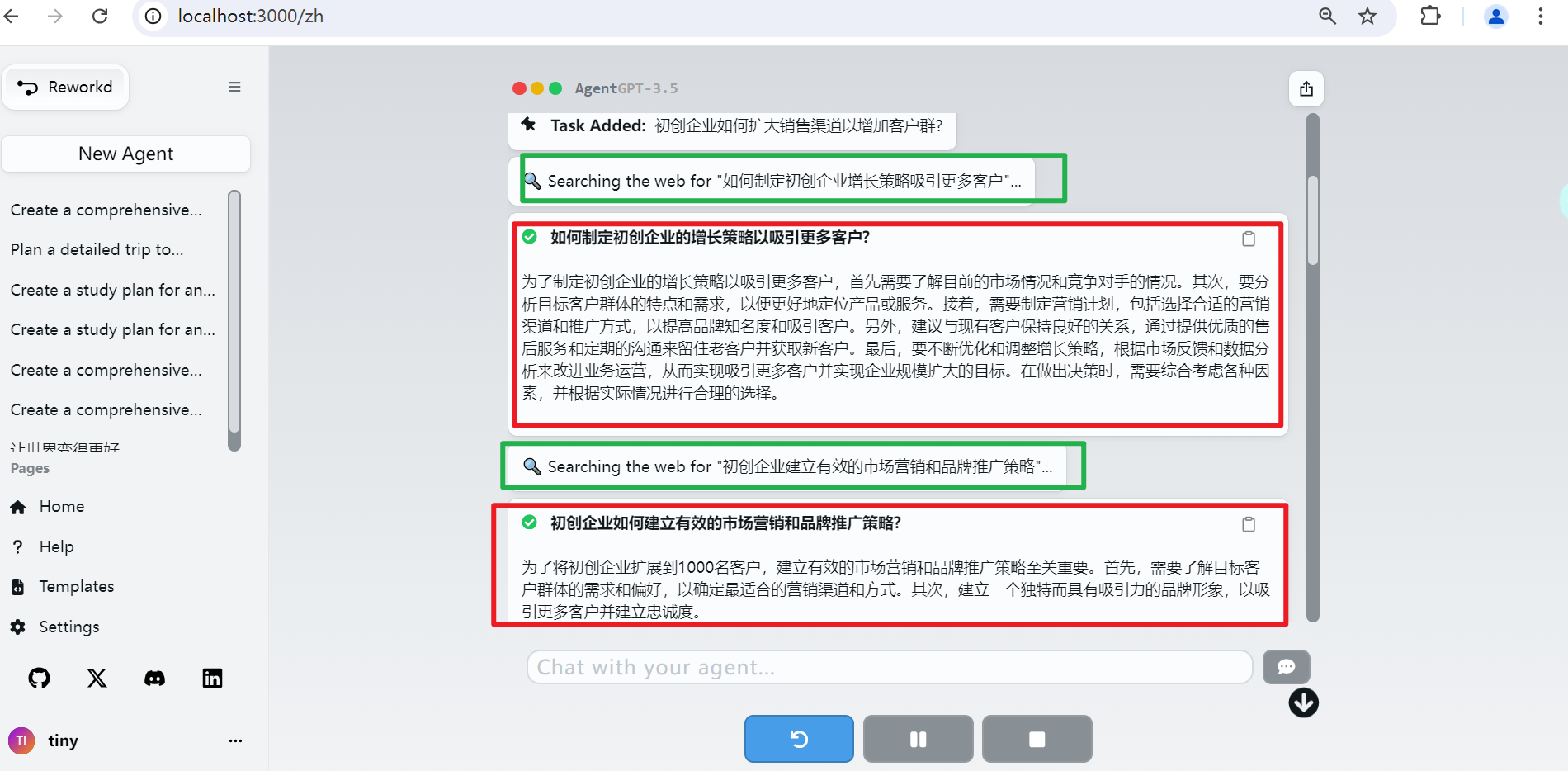
生成总结
在完成所有子任务后,还可以生成总结。如下图所示:
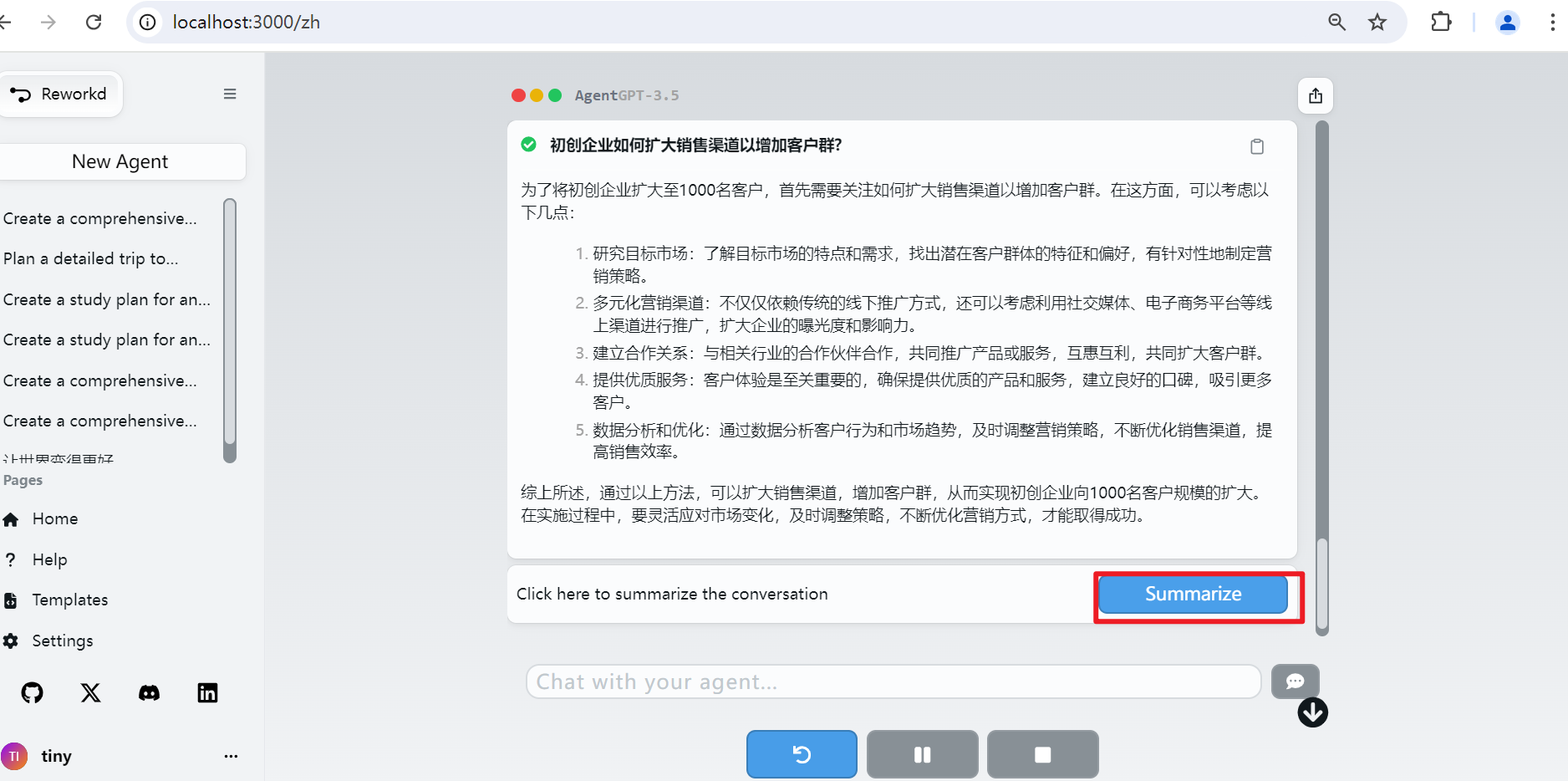
点击“Summarize”按钮,则AgentGPT会根据目标、所有的子任务及其执行结果来生成总结。如下图所示:
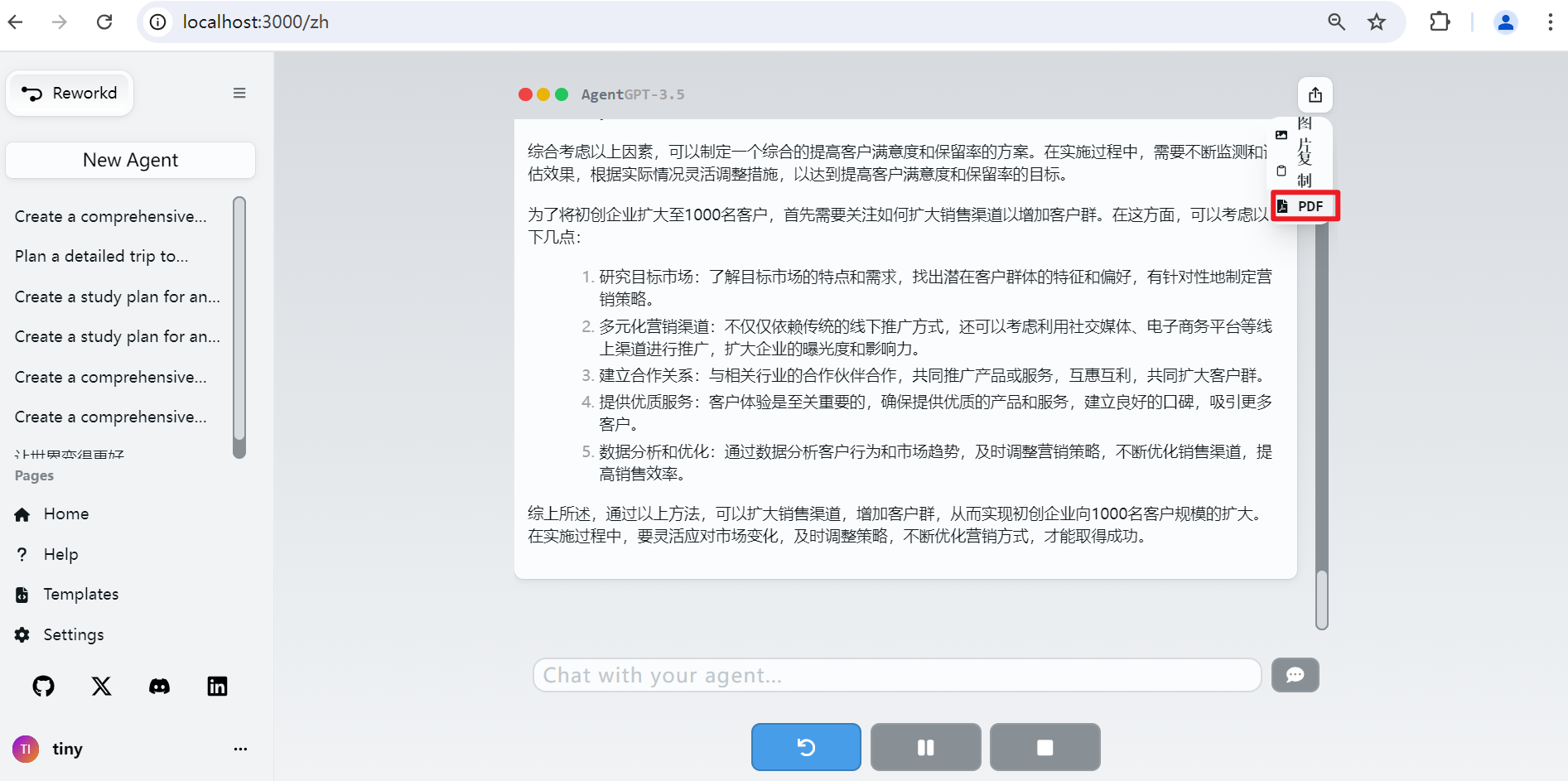
最后,还可以导出为图片或PDF,如上图画红框所示。
运行原理
AgentGPT项目包含前端和后端,主要的运行流程如下:
-
用户输入一个目标,前端向后端发送请求/start(启动目标Agent),后端根据用户的目标构建提示词调用大模型,返回实现目标的子任务列表。
-
前端依次遍历处理每一个子任务,先向后端发送请求/analyze (任务分析请求),传入参数:目标,当前任务及可用的工具列表。后端接收请求,调用大模型对任务进行分析决策,返回如何处理该任务的行动命令(action)。返回示例如下:

-
然后,前端向后端发送请求/execute(任务执行请求),传入参数:目标、当前任务、上一步返回的任务分析结果(包含执行的行动命令)。后端执行参数中指定的行动命令,以完成该任务。返回任务完成的结果。
1
|
AgentGPT中默认集成了些工具命令如:Search(谷歌搜索)、Image(用于素描、绘制或生成图像)、Code(编写和审查代码)、SID(查找私人信息)。
|
-
重复执行2、3步骤,直到所有子任务都执行完成。
-
执行完成后,可以对所有子任务的执行结果进行总结,用户点击总结按钮,前端向后端发送请求/summarize(总结请求),传入参数:目标、所有子任务的执行结果。后端调用大模型生成总结信息并返回。
另外,在第一步前端调用/start返回后会创建agent,并保存agent信息到数据库agent表中。在2、3、5步执行后也会更新agent任务的执行信息到表agent_task(任务执行事件记录)、agentTask(任务执行详细记录)中。所以AgentGPT,其实记录了用户历史的Agent交互记录。
另外,在第一步前端调用/start返回后会创建agent,并保存agent信息到数据库中。在2、3、5步执行后也会保存agent任务的执行信息到数据库中,并更新agent任务的执行状态。所以AgentGPT,其实记录了用户历史的Agent交互记录。
源码解析
AgentGPT项目包含两个部分,前端及后端工程,前端采用next框架,后端采用Uvicorn +FastAPI 架构。
后端源码在reworkd_platform目录下,其代码结构如下:
- db:定义实体对象,与数据库表结构的映射关系,及CRUD操作。
- schemas:主要定义一些请求传输对象的结构及其数据验证信息。如AgentRun、UserBase等对象的字段及数据验证,验证使用Pydantic库。
- services:定义一些通用的服务类,如:AWS的S3存储服务、pinecone向量数据库的添加、查询服务、Token的计算服务、安全加解密服务等。
- tests:测试相关的代码。
- web:处理前端发送的请求。
- /api/agent:agent处理的核心,包含定义处理agent请求的接口,及具体实现逻辑的服务类。
- /api/auth:授权相关操作,定义第三方oauth的授权登录等。
- /api/memory:增加记忆功能,如将任务生成嵌入到向量数据库中,后续可从向量数据库中搜索相似性任务上下文。
- /api/monitoring:出错处理及健康检测接口服务。
接下来我们主要根据运行流程,来深入源码了解其实现细节。
一、前端向后端发送请求/start(启动Agent)
用户输入目标,点击运行后。前端向后端发送请求/start,后端根据用户的目标构建提示词调用大模型,返回实现目标的子任务列表。该请求接口的处理代码在/web/api/agent/views.py中定义,代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
#定义处理post请求"/start"
@router.post(
"/start",
)
async def start_tasks(
req_body: AgentRun = Depends(agent_start_validator),
agent_service: AgentService = Depends(get_agent_service(agent_start_validator)),
) -> NewTasksResponse:
#调用agent_service服务的start_goal_agent方法,传入目标,获取新的任务列表,并返回给前端.
new_tasks = await agent_service.start_goal_agent(goal=req_body.goal)
return NewTasksResponse(newTasks=new_tasks, run_id=req_body.run_id)
|
调用agent_service服务的start_goal_agent方法,传入目标,获取新的任务列表。agent_service的实现类是/web/api/agent/agent_service/open_ai_agent_service.py,其中start_goal_agent方法的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#传入目标,构造提示,调用大模型生成新的任务列表,并按字符串数组格式返回.
async def start_goal_agent(self, *, goal: str) -> List[str]:
#传入提示词模板 start_goal_prompt,构造聊天模型的提示.
prompt = ChatPromptTemplate.from_messages(
[SystemMessagePromptTemplate(prompt=start_goal_prompt)]
)
#计算并设置模型输出的最大token数。OpenAI 计算token数是合并计算 Prompt和 Completion 的总 #token数,要求总 token 数不能超过模型上限(如默认模型 token 上限为 4096).
#计算公式为:max_allowed_tokens(模型许可的最大长度)-prompt_token(提示词的token长度).
self.token_service.calculate_max_tokens(
self.model,
prompt.format_prompt(
goal=goal,
language=self.settings.language,
).to_string(),
)
#调用大模型并进行容错处理,返回生成的新任务列表响应.
completion = await call_model_with_handling(
self.model,
ChatPromptTemplate.from_messages(
[SystemMessagePromptTemplate(prompt=start_goal_prompt)]
),
{"goal": goal, "language": self.settings.language},
settings=self.settings,
callbacks=self.callbacks,
)
#解析大模型返回的响应数据,格式为json的字符串数组
task_output_parser = TaskOutputParser(completed_tasks=[])
tasks = parse_with_handling(task_output_parser, completion)
return tasks
|
这里主要的是使用提示start_goal_prompt,该提示其实是遵循 Plan-and-Solve 框架的提示模板来生成新任务列表,提示信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# Create initial tasks using plan and solve prompting
# https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting
start_goal_prompt = PromptTemplate(
template="""You are a task creation AI called AgentGPT.
You answer in the "{language}" language. You have the following objective "{goal}".
Return a list of search queries that would be required to answer the entirety of the objective.
Limit the list to a maximum of 5 queries. Ensure the queries are as succinct as possible.
For simple questions use a single query.
Return the response as a JSON array of strings. Examples:
query: "Who is considered the best NBA player in the current season?", answer: ["current NBA MVP candidates"]
query: "How does the Olympicpayroll brand currently stand in the market, and what are its prospects and strategies for expansion in NJ, NY, and PA?", answer: ["Olympicpayroll brand comprehensive analysis 2023", "customer reviews of Olympicpayroll.com", "Olympicpayroll market position analysis", "payroll industry trends forecast 2023-2025", "payroll services expansion strategies in NJ, NY, PA"]
query: "How can I create a function to add weight to edges in a digraph using {language}?", answer: ["algorithm to add weight to digraph edge in {language}"]
query: "What is the current weather in New York?", answer: ["current weather in New York"]
query: "5 + 5?", answer: ["Sum of 5 and 5"]
query: "What is a good homemade recipe for KFC-style chicken?", answer: ["KFC style chicken recipe at home"]
query: "What are the nutritional values of almond milk and soy milk?", answer: ["nutritional information of almond milk", "nutritional information of soy milk"]""",
input_variables=["goal", "language"],
)
|
翻译如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
使用plan and solve提示创建初始任务列表
# https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting
开始目标提示模板:
模板内容为:“你是一个名为AgentGPT的任务创建AI。
你用{language}回答问题。你的目标是{goal}。
返回一个需要回答整个目标的搜索查询列表。
将列表限制在最多5个查询。确保查询尽可能简洁。
对于简单的问题使用单个查询。
返回JSON格式的字符串数组响应。示例:
查询:“谁被认为是当前赛季NBA最好的球员?”,答案:“当前NBA MVP候选人”
查询:“奥林匹克支付品牌在市场上目前处于何种地位?它在新泽西州、纽约州和宾夕法尼亚州的扩张前景和战略是什么?”,答案:“奥林匹克支付品牌全面分析2023”、“Olympicpayroll.com客户评价”、“奥林匹克支付市场地位分析”、“薪资行业趋势预测2023-2025”、“薪资服务在新泽西州、纽约州和宾夕法尼亚州的扩张策略”
查询:“如何使用 {language} 创建一个为有向图中的边添加权重的函数?”,答案:“{语言} 中为有向图边添加权重的算法”
查询:“纽约的当前天气如何?”,答案:“纽约的当前天气”
查询:“5 + 5等于多少?”,答案:“5和5的和”
查询:“有什么好的自制肯德基鸡肉配方?”,答案:“在家制作肯德基风格鸡肉的食谱”
查询:“杏仁奶和豆浆的营养成分是什么?”,答案:“杏仁奶的营养信息”,“豆浆的营养信息”
|
二、前端先向后端发送请求/analyze (任务分析请求)
前端依次遍历处理每一个子任务,先向后端发送请求/analyze (任务分析请求),传入参数:目标,当前任务及可用的工具列表。后端接收请求,调用大模型对任务进行分析决策,返回如何处理该任务的行动命令(action)。
该请求接口的处理代码同样在/web/api/agent/views.py中定义,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
#定义处理post请求"/analyze"
@router.post("/analyze")
async def analyze_tasks(
req_body: AgentTaskAnalyze = Depends(agent_analyze_validator),
agent_service: AgentService = Depends(get_agent_service(agent_analyze_validator)),
) -> Analysis:
#调用agent_service服务的analyze_task_agent方法,传入目标,当前任务,可用的工具列表.返回如何处理 #该任务的行动命令
return await agent_service.analyze_task_agent(
goal=req_body.goal,
task=req_body.task or "",
tool_names=req_body.tool_names or [],
)
|
调用agent_service服务的analyze_task_agent方法。该方法实际调用大模型对任务进行分析决策,返回需要执行的行动命令。实现类是/web/api/agent/agent_service/open_ai_agent_service.py,其中该方法的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
#根据传入的目标、当前任务、可用工具列表,构造提示,调用大模型获取如何处理该任务的行动命令,
async def analyze_task_agent(
self, *, goal: str, task: str, tool_names: List[str]
) -> Analysis:
#获取可用工具列表
user_tools = await get_user_tools(tool_names, self.user, self.oauth_crud)
#构建Function Calling 调用工具的信息描述,让大模型来选择使用哪个工具(或Function),大模型实际 #上并不会真的执行函数,它会根据你给与它的上下文信息来推断要执行的函数,以及函数对应的Arguments, #然后以JSON的方式输出函数名和参数信息,随后就可以根据JSON信息来真正的执行Function。
functions = list(map(get_tool_function, user_tools))
#使用analyze_task_prompt提示模板构建提示,传入目标、当前任务
prompt = analyze_task_prompt.format_prompt(
goal=goal,
task=task,
language=self.settings.language,
)
#计算并设置模型输出的最大token数,原因之前已经说明
self.token_service.calculate_max_tokens(
self.model,
prompt.to_string(),
str(functions),
)
#调用大模型并进行容错处理,返回响应结果.返回下一步要使用哪个工具(或Function)的决策。
message = await openai_error_handler(
func=self.model.apredict_messages,
messages=prompt.to_messages(),
functions=functions,
settings=self.settings,
callbacks=self.callbacks,
)
#获取大模型响应的下一步需要执行的函数信息及其参数
function_call = message.additional_kwargs.get("function_call", {})
completion = function_call.get("arguments", "")
try:
#解析调用参数
pydantic_parser = PydanticOutputParser(pydantic_object=AnalysisArguments)
analysis_arguments = parse_with_handling(pydantic_parser, completion)
#构造返回数据对象Analysis,格式是:{action:str, reasoning: str,arg: str}
return Analysis(
action=function_call.get("name", get_tool_name(get_default_tool())),
**analysis_arguments.dict(),
)
except (OpenAIError, ValidationError):
return Analysis.get_default_analysis(task)
|
这里关键使用的提示是analyze_task_prompt,该提示信息如下:
1
2
3
4
5
6
7
8
9
10
11
|
template="""
High level objective: "{goal}"
Current task: "{task}"
Based on this information, use the best function to make progress or accomplish the task entirely.
Select the correct function by being smart and efficient. Ensure "reasoning" and only "reasoning" is in the
{language} language.
Note you MUST select a function.
""",
input_variables=["goal", "task", "language"],
|
翻译如下:
1
2
3
4
5
6
7
8
9
10
|
template= " "
高级目标:“{goal}”
当前任务:“{task}”
基于这些信息,选择最佳的函数来取得进展或完成任务。
聪明高效地选择正确的函数。确保“推理”并且只有“推理”使用在{language}中定义的语言。
注意你必须选择一个函数。
”“”,
Input_variables =["goal", "task", "language"],
|
三、前端再向后端发送请求/execute(任务执行请求)
上一步对任务进行分析决策,获取完成该任务要执行的行动命令(action)。然后前端向后端发送请求/execute(任务执行请求),传入参数:目标、当前任务、上一步返回的分析决策结果(包含行动命令)。后端执行参数中指定的行动命令,以完成该任务,返回任务完成的结果。
该请求接口的处理代码同样在/web/api/agent/views.py中定义,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#定义处理post请求"/execute"
@router.post("/execute")
async def execute_tasks(
req_body: AgentTaskExecute = Depends(agent_execute_validator),
agent_service: AgentService = Depends(
get_agent_service(validator=agent_execute_validator, streaming=True),
),
) -> FastAPIStreamingResponse:
#调用agent_service服务的execute_task_agent方法,传入参数:目标、当前任务、上一步的分析决策。 #返回执行动作的结果.
return await agent_service.execute_task_agent(
goal=req_body.goal or "",
task=req_body.task or "",
analysis=req_body.analysis,
)
|
调用agent_service服务的execute_task_agent方法。该方法执行上一步分析决策的行动命令,并返回执行结果。实现类是/web/api/agent/agent_service/open_ai_agent_service.py,其中该方法的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 根据命令名称获取对应的工具类,实例化工具类,调用其call方法进行执行,返回执行结果。
async def execute_task_agent(
self,
*,
goal: str,
task: str,
analysis: Analysis,
) -> StreamingResponse:
# TODO: 更成熟的max_tokens计算方法
if self.model.max_tokens > 3000:
self.model.max_tokens = max(self.model.max_tokens - 1000, 3000)
#根据命令名称获取对应的工具类
tool_class = get_tool_from_name(analysis.action)
#实例化工具类,调用其call方法进行执行
return await tool_class(self.model, self.settings.language).call(
goal,
task,
analysis.arg,
self.user,
self.oauth_crud,
)
|
AgentGPT中默认集成了些工具,如:Search(谷歌搜索)、Image(用于素描、绘制或生成图像)、Code(编写和审查代码)、SID(查找私人信息)。
四、前端向后端发送请求/summarize(总结请求)
当所有子任务都执行完成后,可以对执行结果进行总结,用户点击总结按钮,前端向后端发送请求/summarize(总结请求),传入参数:目标、所有子任务的执行结果。后端调用大模型生成总结信息并返回。
该请求接口的处理代码同样在/web/api/agent/views.py中定义,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#定义处理post请求"/summarize"
@router.post("/summarize")
async def summarize(
req_body: AgentSummarize = Depends(agent_summarize_validator),
agent_service: AgentService = Depends(
get_agent_service(
validator=agent_summarize_validator,
streaming=True,
llm_model="gpt-3.5-turbo-16k",
),
),
) -> FastAPIStreamingResponse:
#调用agent_service服务的summarize_task_agent方法,传入参数:目标,所有子任务的执行结果列表。返回 #生成的总结信息。
return await agent_service.summarize_task_agent(
goal=req_body.goal or "",
results=req_body.results,
)
|
调用agent_service服务的summarize_task_agent方法。该方法根据所有子任务的执行结果列表、目标构建提示,调用大模型生成总结信息响应。实现类是/web/api/agent/agent_service/open_ai_agent_service.py,其中该方法的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#根据所有子任务的执行结果列表、目标构建提示,调用大模型生成总结信息响应
async def summarize_task_agent(
self,
*,
goal: str,
results: List[str],
) -> FastAPIStreamingResponse:
self.model.model_name = "gpt-3.5-turbo-16k"
self.model.max_tokens = 8000 # Total tokens = prompt tokens + completion tokens
snippet_max_tokens = 7000 # Leave room for the rest of the prompt
#计算模型输出的最大token数
text_tokens = self.token_service.tokenize("".join(results))
#截取最大token数范围内的文本
text = self.token_service.detokenize(text_tokens[0:snippet_max_tokens])
logger.info(f"Summarizing text: {text}")
#调用大模型,生成总结响应
return summarize(
model=self.model,
language=self.settings.language,
goal=goal,
text=text,
)
|
执行 summarize 方法,其内部其实是构建langchain 的chain,调用大模型,生成总结响应。 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def summarize(
model: BaseChatModel,
language: str,
goal: str,
text: str,
) -> FastAPIStreamingResponse:
from reworkd_platform.web.api.agent.prompts import summarize_prompt
#构建langchain 的chain
chain = LLMChain(llm=model, prompt=summarize_prompt)
#生成总结并流式响应返回
return StreamingResponse.from_chain(
chain,
{
"goal": goal,
"language": language,
"text": text,
},
media_type="text/event-stream",
)
|
五、前端获取外部的工具列表
AgentGPT前端在启动Agent之前,会请求接口/tools获取用户的可用工具列表。在向后端发送请求/analyze (任务分析请求),对任务进行分析决策,获取下一步如何处理该任务的行动命令时,作为可用工具列表参数传入。
该请求接口的处理代码在/web/api/agent/views.py中定义,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#定义处理get请求"/tools"
router.get("/tools")
async def get_user_tools() -> ToolsResponse:
#获取外部的工具列表,默认定义的有三个:Image(用于素描、绘制或生成图像)、Code(编写和审查代码)、
#SID(查找私人信息)
tools = get_external_tools()
#构建ToolModel对象数组,ToolModel对象包含名称、描述、颜色、图片URL
formatted_tools = [
ToolModel(
name=get_tool_name(tool),
description=tool.public_description,
color="TODO: Change to image of tool",
image_url=tool.image_url,
)
for tool in tools
if tool.available()
]
return ToolsResponse(tools=formatted_tools)
|
以上这些就是AgentGPT的核心接口。
剩下的还有些非主流程的辅助功能,如:
- 授权相关操作(如第三方oauth的授权登录),接口定义在
reworkd_platform/web/api/auth/views.py中。
- 出错处理及健康检测接口服务,接口定义在
reworkd_platform/web/api/monitoring/views.py中。
实现也相对比较简单,这里就不再列出来,有兴趣的朋友,可以进到相应的目录文件中查看。
项目相关代码及文件放在网盘中,地址:
链接:https://pan.quark.cn/s/11ca682f0ec7
提取码:KXJr
参考
https://github.com/reworkd/AgentGPT
https://docs.reworkd.ai/development/setup