4 手把手搭建第一个 RAG 实战:实现本地文档智能问答
4.1 项目概述
本文将带领你从零开始搭建基于 RAG(检索增强生成)的知识问答系统,实现文档上传、内容解析与并基于检索文档内容进行智能问答。系统支持 PDF、DOCX、TXT、MD 等多格式文档,通过向量数据库存储文档向量,结合大语言模型(LLM)生成准确回答,并具有流式输出功能提升用户体验,有效解决 LLM 的静态知识局限与 “幻觉” 问题。
核心功能如下:
- 支持上传 PDF/DOCX/TXT/MD 格式文档。
- 自动解析文档内容、进行向量化并存储在向量数据库中。
- 基于用户问题检索相关文档片段,结合检索的文档片段、上下文生成准确回答。
- 支持多轮对话、理解上下文语境和流式输出。
- 提供简洁的 Web 交互界面。
4.2 工作流程
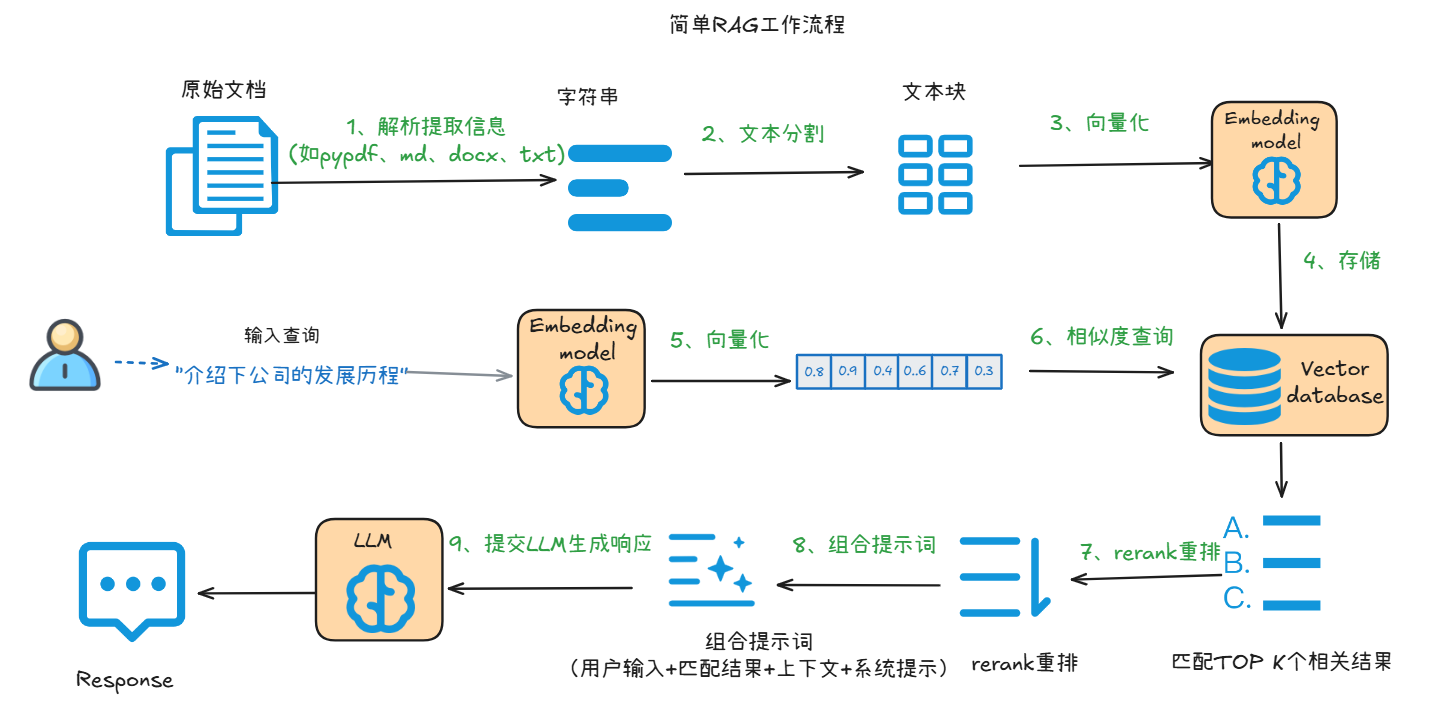
上图展示了基于RAG的知识库问答系统的工作流程,整体可分为文档处理(知识入库)和用户查询(知识检索与回答) 两大阶段,以下分步骤解析:
一、文档处理阶段(知识入库)
- 1. 解析提取信息:对原始文档(如 PDF、Markdown、Word、txt 格式),通过工具(如
pypdf库、文档解析工具)提取文本内容,转化为字符串形式。 - 2. 文本分割:将提取的长字符串切割为若干 “文本块”(Chunk),确保每个文本块语义相对完整(比如按段落、固定字数分割),便于后续向量化和检索。
- 3. 向量化:利用Embedding 模型(一种将文本转化为数值向量的模型),把每个文本块转化为高维向量。向量的数值能够表征文本的语义信息,语义越相似的文本,向量距离越近。
- 4. 存储:将这些文本向量存入向量数据库(Vector Database),支持后续快速的相似度查询。
二、用户查询阶段(知识检索与回答)
- 5. 用户查询向量化:用户输入查询(如 “介绍下公司的发展历程”)后,同样通过上述Embedding 模型,将查询文本转化为向量。
- 6. 相似度查询:查询向量数据库中,计算 “用户查询向量” 与 “已存储的文本块向量” 的相似度,筛选出TOP K 个最相关的文本块(即与用户问题语义最匹配的知识片段)。
- 7. 结果重排(Rerank):对 TOP K相关的结果进一步做重排,确保最相关的内容优先被选用。
- 8. 组合提示词:将 “用户输入、重排后的知识片段 、上下文补充(可选)、系统提示(如 “基于提供的信息生成简洁回答”)” 整合为结构化提示词(Prompt)。
- 9. 提交 LLM 生成响应:将组合好的提示词输入大语言模型(LLM),LLM 基于这些信息理解用户需求,生成最终的自然语言回答(Response)。
4.3 架构设计
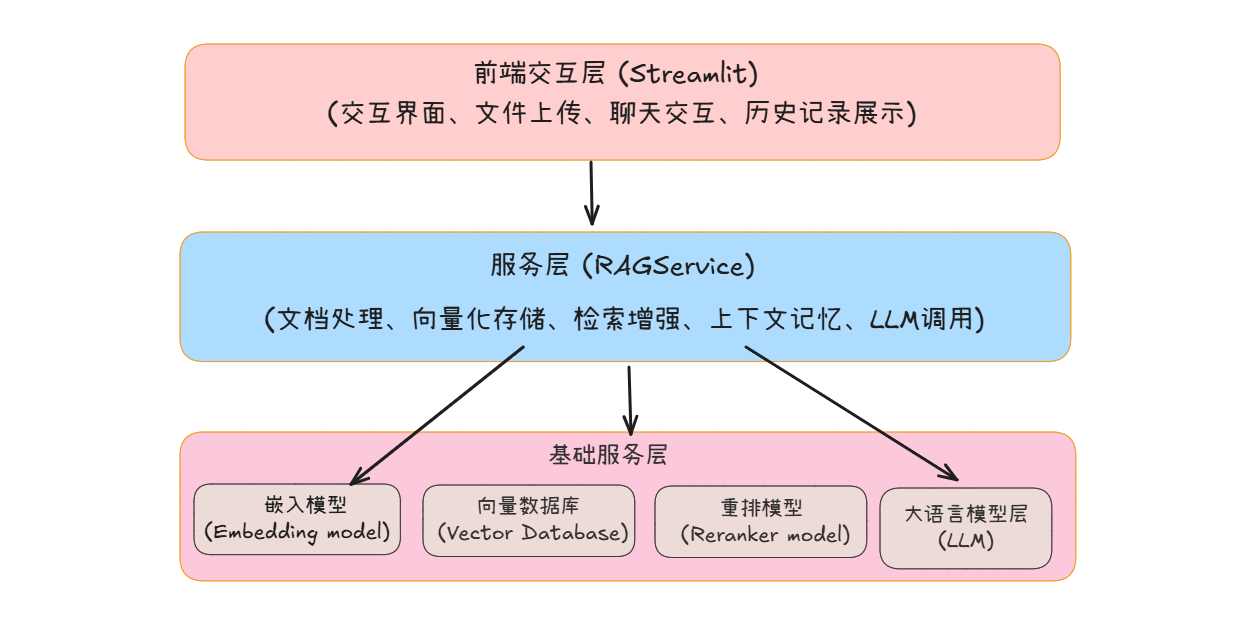
系统采用模块化设计,主要包含以下组件:
-
前端层:基于 Streamlit 构建,负责与用户直接交互,包括提供交互界面、支持文件上传、实现聊天交互、支持连续多轮对话、流式输出。
-
服务层:核心业务逻辑,封装了 RAG 技术的核心流程:
- 文档处理:对用户上传的文档进行解析、分块(将长文档拆分为短文本片段,便于后续处理)。
- 向量化存储:调用嵌入模型,将分块后的文本片段转换为语义向量,再批量写入向量数据库,完成知识入库。
- 检索增强:用户发起查询时,先通过向量数据库检索出Top K 候选文本片段,再调用重排模型对候选结果做精细化排序,筛选出最相关的内容,为 LLM 提供精准知识支撑。
- 上下文记忆:记录对话的上下文信息,使大语言模型能理解多轮对话的逻辑(如连续追问时,模型能基于历史对话回答)。
- LLM 调用:封装对 “大语言模型(LLM)” 的调用逻辑,将 “
系统提示词 + 用户当前问题 + 检索到的相关文本 + 对话上下文” 整合为提示词,调用大语言模型生成准确回答,并将结果回传至前端。
-
基础服务层:
为上层业务提供核心技术能力支撑,包含三大核心组件:
- 嵌入模型(Embedding model):将自然语言文本转换为高维语义向量,是实现文本相似度检索的基础。
- 向量数据库(Vector Database):专用于存储和快速检索向量数据的数据库,支持高效的相似性检索(如余弦相似度计算),是 RAG 流程的核心存储载体。
- 重排模型(Reranker Model):对向量检索得到的 Top K 候选结果做二次精准排序,提升 “相关文本片段” 的匹配精度;
- 大语言模型层(LLM):即大语言模型(如 GPT5、Qwen、 DeepSeek等),负责基于用户问题和检索到的文本,生成自然语言回答。
4.4 技术选型
- 前端框架:Streamlit(快速构建交互式 Web 应用)。
- 文档处理:LangChain(文档加载、文本分块、记忆上下文管理)。
- 嵌入模型:支持 Qwen、OpenAI等第三方提供的嵌入模型,以及支持本地部署模型
bge-small-zh-v1.5。 - 向量数据库:Chroma(轻量级嵌入式向量数据库)。
- 大语言模型:支持 Qwen、OpenAI、DeepSeek 等模型。
- 文档处理:pypdf(PDF 解析)、docx2txt(DOCX 解析)
- 环境管理:python-dotenv(环境变量管理)。
- 开发语言:Python 3.8+。
4.5 代码实现
4.5.1 项目结构搭建
项目完成后,目录结构如下:
|
|
4.5.2 环境准备
一、配置Conda 虚拟环境(安装 Conda,若未安装)
- 下载地址:https://docs.conda.io/en/latest/miniconda.html(conda 轻量化,推荐)
- 安装流程:
- Windows:双击安装包,勾选 “Add Miniconda3 to PATH”(方便命令行调用)
- Mac/Linux:执行安装脚本,按提示完成(默认会添加环境变量)
- 验证安装:打开终端 / 命令提示符,输入
conda --version,显示版本号则成功
二、创建并激活 Conda 虚拟环境
-
打开终端 / 命令提示符,执行以下命令创建虚拟环境(Python 版本指定 3.11):
1 2# 创建名为rag-env的虚拟环境(名称可随意),指定Python 3.11 conda create -n rag-env python=3.11过程中会提示安装依赖,输入
y确认。 -
激活虚拟环境:
-
Windows(命令提示符):
1conda activate rag-env # 若执行不了,尝试:conda.bat activate rag-env -
Mac/Linux:
1conda activate rag-env
激活成功后,终端前缀会显示
(rag-env) -
-
(可选)配置 Conda 镜像源(加速依赖安装,国内用户推荐):
1 2 3 4# 添加清华镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ config --set show_channel_urls yes
三、安装项目依赖
-
创建项目文件夹并进入:
1 2# 创建文件夹 mkdir simple_rag_assistant && cd simple_rag_assistant -
创建
requirements.txt文件,添加依赖包如下:1 2 3 4 5 6 7 8 9 10 11 12streamlit==1.46.0 langchain==0.3.26 langchain-chroma==0.2.4 langchain-community==0.3.27 langchain-core==0.3.66 langchain-deepseek==0.1.3 langchain-openai==0.3.19 python-dotenv==1.1.0 pypdf==5.6.1 dashscope==1.23.5 tenacity==9.1.2 sentence-transformers==5.1.2 # HuggingFace嵌入模型依赖 -
用 pip 安装依赖(Conda 环境中已自带 pip,无需额外配置):
1pip install -r requirements.txt若安装缓慢,也可临时使用中科大镜像或清华 pip 镜像安装(要检查下,不确定是否可用):
1 2 3 4 5 6# 1. 阿里云(稳定,国内首选) pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ # 2. 清华大学(学术镜像,包全更新快) # pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ # 3. 腾讯云(企业级镜像,速度稳定) # pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple/
四、配置环境变量
-
在项目根目录创建
.env文件(注意文件名前有小数点):1 2 3 4 5 6 7 8 9 10 11# Qwen(千问)模型配置(必填,默认使用) QWEN_API_KEY=你的千问API密钥 QWEN_BASE_URL=你的千问API基础地址(如https://dashscope.aliyuncs.com/compatible-mode/v1) # OpenAI模型配置(可选,如需切换使用) OPENAI_API_KEY=你的OpenAI API密钥 OPENAI_BASE_URL=你的OpenAI API基础地址 # DeepSeek模型配置(可选,如需切换使用) DEEPSEEK_API_KEY=你的DeepSeek API密钥 DEEPSEEK_BASE_URL=你的DeepSeek API基础地址说明:
- 默认使用通义千问的大语言模型
qwen-plus以及向量模型text-embedding-v4。千问 API 密钥获取:登录阿里云百炼大模型平台(https://dashscope.console.aliyun.com/)申请,新用户默认有100W token的免费额度。 - 其它 API 密钥根据实际使用需求配置,无需使用则可留空。
- 默认使用通义千问的大语言模型
4.5.3 核心模块实现
1 自定义嵌入模型适配(models/custom_dashscope_embedding.py)
该类实现千问嵌入模型与 LangChain 的适配,负责将文本转换为向量。
由于在使用官方提供的类from langchain_community.embeddings import DashScopeEmbeddings进行向量化时,报错:batch size is invalid,it should not be larger than 10.: input.contents。该错误原因是langchain_community 包中的的DashScopeEmbeddings类在处理文档时,默认的批量大小超过了 DashScope API 的限制。故重写了该类,调整了默认BATCH_SIZE的大小,以解决批量请求超限问题。
在项目目录下创建models 文件夹,并在该文件夹下创建custom_dashscope_embedding.py文件,代码如下:
|
|
2 嵌入模型调用(models/langchain_embedding.py)
该文件统一初始化不同来源的文本嵌入模型。支持千问(Qwen)、OpenAI 和本地 BGE 模型,方便开发者根据需求切换,无需修改核心逻辑。
在models文件夹下创建文件langchain_embedding.py,代码如下:
|
|
提供了 3 种嵌入模型,只需选择其中一直即可,每种模型的初始化逻辑如下:
-
**
qwen(千问):**默认,这里使用的是千问向量模型text-embedding-v4。必须配置QWEN_API_KEY和QWEN_BASE_URL两个环境变量。 -
**openai:**需在环境变量中配置
OPENAI_API_KEY,若使用第三方代理还需配置OPENAI_BASE_URL(自定义接口地址)。 -
**local_bge_small:**本地加载向量模型,不访问第三方提供的模型服务。这里使用的是北京智源研究院(BAAI)开发的轻量级中文文本嵌入模型
bge-small-zh-v1.5,对资源要求不高,适合资源受限场景。若使用本地加载向量模型,执行以下步骤:
-
首先安装必要的 Python 库。
1pip install transformers sentence-transformers torch --upgrade -
下载向量模型文件,两种方式下载:
-
手动下载:可从HuggingFace 或 魔塔地址下载模型文件,放到当前目录的
./models_data/bge-small-zh-v1.5路径下。下载文件:config.json(模型配置)、model.safetensors(模型权重)、tokenizer.json、tokenizer_config.json、vocab.txt(分词器文件)。设置model_path 为下载的本地路径地址。 -
自动下载:设置
model_path为"BAAI/bge-small-zh-v1.5",首次运行时 SDK 会自动下载(需联网)。下载默认存储路径如下:Windows:``C:\Users\用户名.cache\huggingface\transformers
)Linux/Mac:
~/.cache/huggingface/transformers下载完成后,后续运行代码会直接从缓存加载,无需重复下载。
-
-
加载模型:通过 LangChain 库中
HuggingFaceEmbeddings加载。-
配置为 CPU 运行(可改
cuda用 GPU); -
对输出向量归一化(方便后续相似度计算)。
-
-
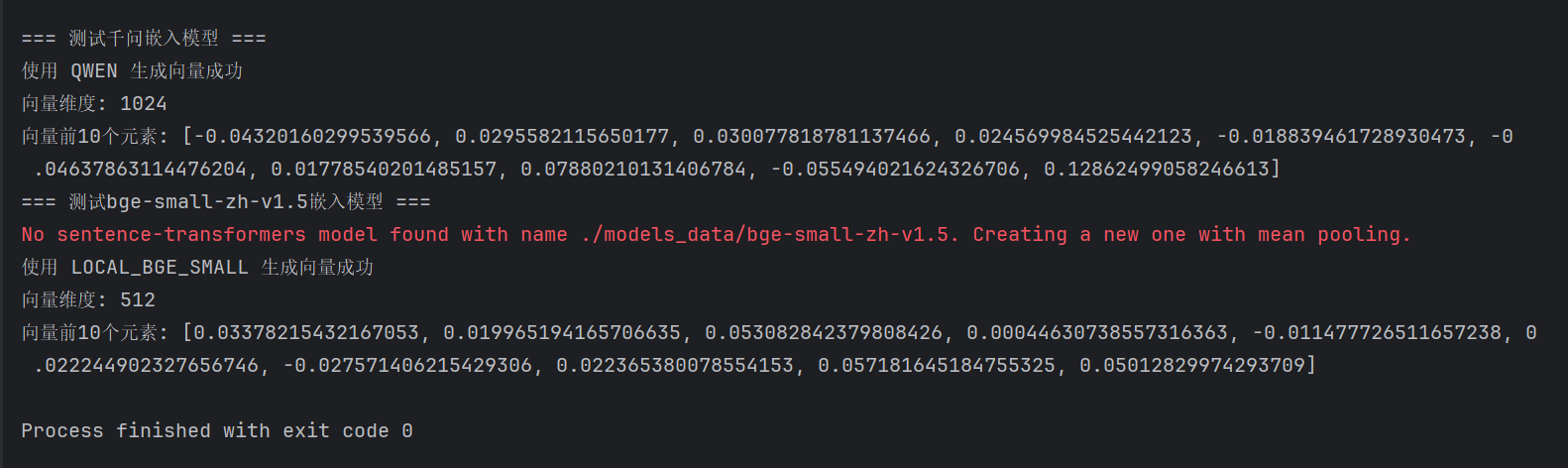
测试嵌入模型
|
|
运行结果如下:
4 LLM模型调用(langchain_llm.py)
基于 LangChain 框架,封装LLM的调用,实现从环境变量读取配置、校验参数,返回模型聊天实例ChatOpenAI。可适配兼容openAI 接口规范的模型服务,如千问(Qwen)、DeepSeek、OpenAI、智谱(Zhipu)等,可配置MODEL_CONFIG_MAP灵活扩展,默认使用千问模型。
在models文件夹下创建文件langchain_llm.py,代码如下:
|
|
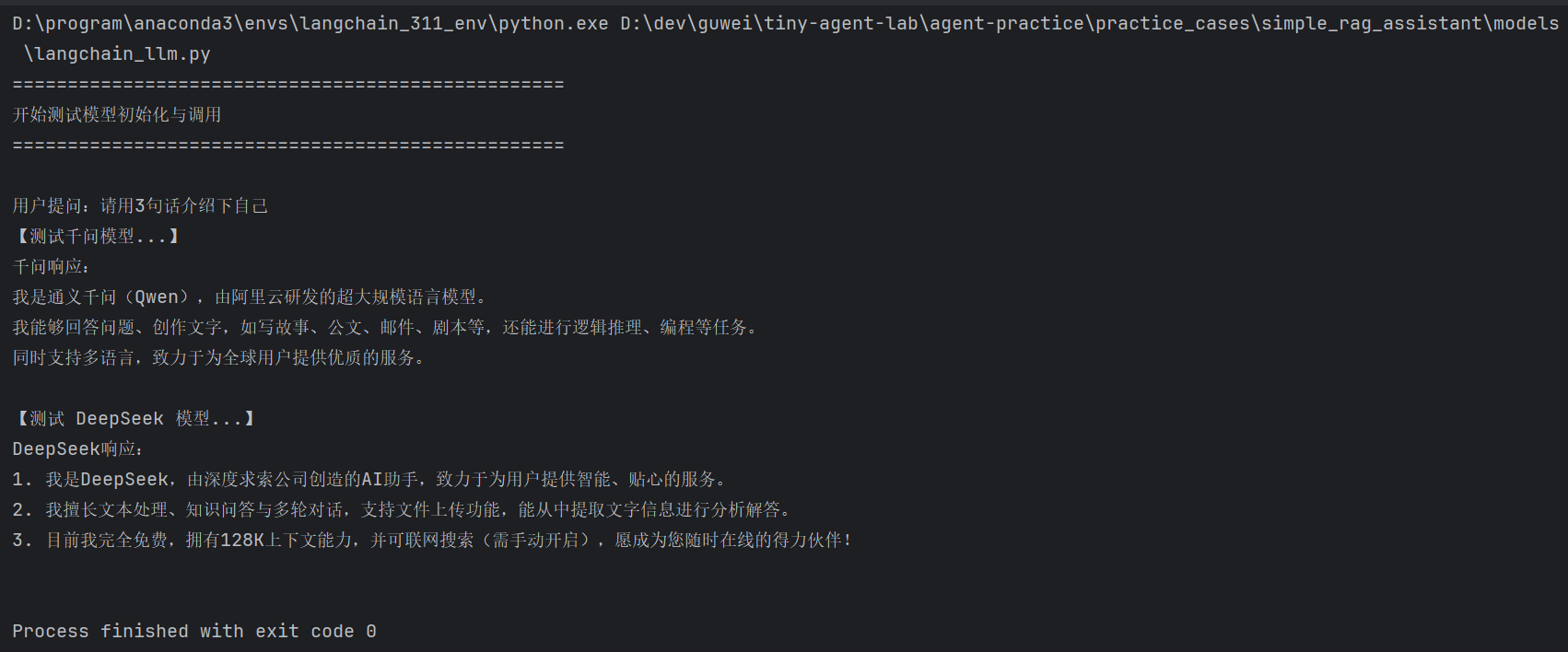
测试LLM模型
|
|
运行结果如下:
5 重排模型调用(reranker_model.py)
初始化重排模型,用于对检索阶段召回的候选文档进行语义相关性重排,提升检索精度。
在models文件夹下创建文件reranker_model.py,代码如下:
|
|
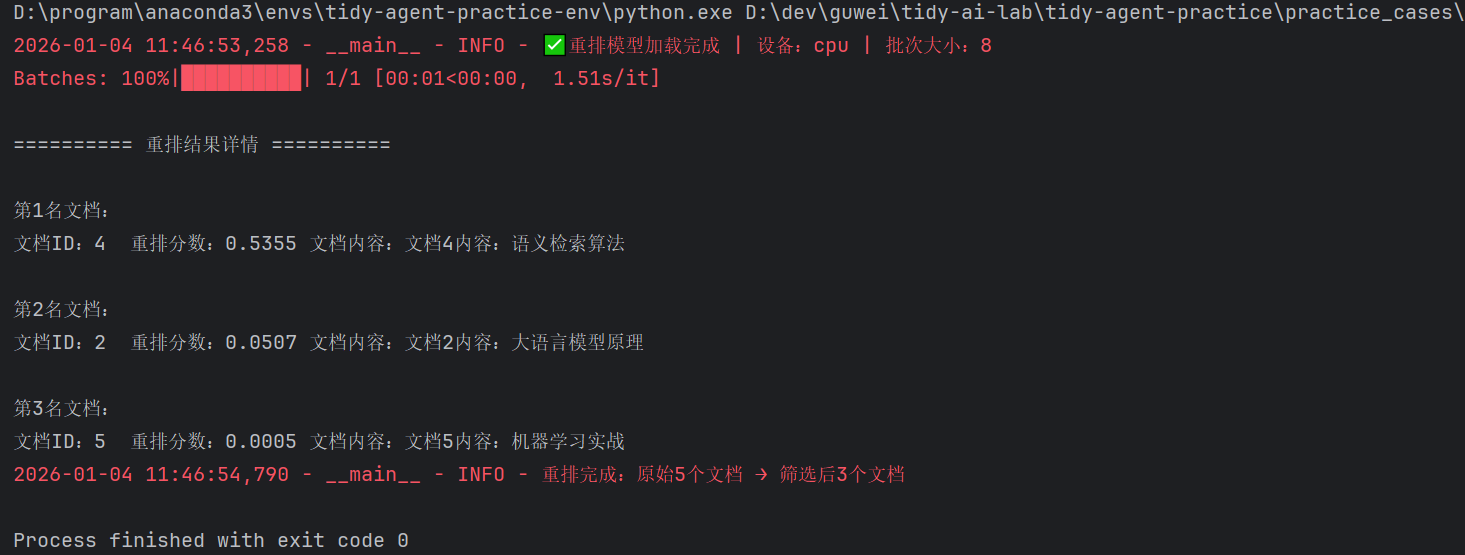
测试重排模型
|
|
执行结果如下:
6 RAG 核心服务(rag_service_stream.py)
该类实现完整检索增强生成(RAG)的核心逻辑:文档处理、向量存储、检索和回答生成。基于 LangChain 构建,核心目标是让大语言模型(LLM)结合上传的文档知识进行问答,解决纯 LLM 可能存在的事实性错误、知识时效性等问题。
在项目目录下创建services文件夹,在该文件夹下创建文件rag_service_stream.py。
一、引入依赖
|
|
二、创建RAGService类并初始化
|
|
三、文档处理:process_document(file)
处理用户上传的文档,解析、分块、向量化、并存储到向量数据库。
|
|
负责将用户上传的文档转换为向量并存储,流程如下:
-
文件有效性校验与临时文件创建:
-
校验文件对象是否包含
name(文件名)和getvalue()(获取二进制内容)方法; -
通过
tempfile.NamedTemporaryFile创建临时文件,写入上传文件的二进制内容(避免直接操作内存数据)。
-
-
文档加载(按格式适配):
根据文件后缀选择对应的 LangChain 加载器,支持 4 种格式:
文件格式 加载器 核心作用 PDF PyPDFLoader解析 PDF 每页内容,生成 Document 对象 DOCX Docx2txtLoader提取 DOCX 文本内容(忽略格式) TXT/MD TextLoader读取纯文本,指定 UTF-8 编码 -
文本分块(解决长文本问题):
使用
RecursiveCharacterTextSplitter进行智能分块,核心配置:chunk_size=1000:每个文本片段最多 1000 字符(适配 LLM 上下文窗口);chunk_overlap=200:片段间重叠 200 字符(避免上下文断裂,比如一个事件描述跨片段);separators=["\n\n", "\n", "。", " ", ""]:优先按大分隔符(如\n\n段落)分割,分割失败再用小分隔符(如。中文句末),最大程度保证语义完整性。
-
向量化存储:
负责将文本(问题、文档片段)转换为高维向量,是「检索」的核心基础,并存入向量数据库中。
- 若向量数据库已存在(
self.vectordb非空),直接添加新分块; - 若不存在,通过
Chroma.from_documents初始化数据库并写入分块向量,同时指定持久化路径。
- 若向量数据库已存在(
-
临时文件清理:
通过
finally块确保无论处理成功 / 失败,临时文件都会被删除,避免磁盘占用。
四、问答生成:get_answer_stream(question, chat_history)
该方法是 RAG(检索增强生成)的核心执行入口,实现检索相关文档→重排→结合历史对话→调用LLM流式生成输出。核心目标是:让 LLM 基于「用户问题 + 历史对话 + 相关文档片段」生成精准、有依据的答案,同时支持上下文连贯对话,流式输出。
|
|
流程如下:
-
前置校验
-
检查向量数据库是否初始化(即是否已上传文档) 。
-
检查用户问题是否有效(非空字符串)。
-
-
对话历史加载
通过
ConversationBufferWindowMemory(滑动窗口记忆)管理对话历史,配置k=50,仅保留最近 50 轮对话(1 轮 = 1 次用户提问 + 1 次助手回答),既保证对话连贯性,又避免长对话导致的 Token 超限问题。 -
检索相关文档(获取回答的事实依据)
基于向量检索技术,从已上传文档中提取与用户问题语义相似的文本片段:
-
将向量数据库转为检索器(
self.vectordb.as_retriever); -
配置
search_kwargs={"k": 5}:检索与用户问题最相关的 5 个文本片段(k值可调整,平衡相关性与上下文长度); -
提取检索结果的文本内容,拼接为
context_text(供 LLM 参考)。
-
-
检索文档重排(提升文档相关性精度)
对原始检索结果进行精细化筛选,进一步提升文档与问题的匹配度:
- 若配置了重排模型(
self.reranker_model),则调用模型对原始检索的文本片段进行重排; - 重排规则:按「相关性分数」筛选 Top-N 个片段(
top_n可配置),并过滤分数低于阈值(score_threshold)的片段; - 降级处理:若重排后无符合条件的片段,则默认选取原始检索结果的前 N 个片段。
- 若配置了重排模型(
-
组合提示词
- 初始化上下文对话列表:combine_contexts = []。
- 添加历史对话记忆:从记忆中加载最近对话列表(Message对象)到上下文对话中,让 LLM 清晰识别历史交互逻辑。
- 定义提示词模板(
system_prompt):定义 LLM 的角色、回答规则,如:仅使用提供的文档片段回答,无相关信息时明确告知,不编造内容。 - 格式化提示模板:将
context_text(检索到的文档)、question(当前问题) 格式化提示模板,生成结构化的final_prompt,并作为用户输入添加到上下文对话中。
-
流式调用LLM输出结果及记忆更新
实现流式输出回答,并将本次交互存入记忆以支撑后续对话:
- 流式生成回答:调用
self.llm.stream(combine_contexts),将完整上下文提交给 LLM,逐块读取生成器中的响应片段并实时返回给用户,同时将片段拼接为self.current_stream_answer(完整答案); - 对话记忆更新:当完整答案生成后,将本次问答对(用户问题
question+ 完整答案self.current_stream_answer)存入记忆ConversationBufferWindowMemory,供下一轮对话。
流式输出提升用户体验,记忆更新保障下一轮对话可复用本次交互信息,维持上下文连贯。
- 流式生成回答:调用
五、清空数据库clear_database()
支持重新上传文档、清空历史知识。
|
|
清空 Chroma 向量数据库的集合内数据(reset_collection)。
7 前端界面(main.py)
通过 Streamlit 框架搭建 Web 交互界面,通过 “上传文档→提问” 的操作,获得基于文档的精准回答,同时支持流式输出(边生成边展示)和聊天连续性。
|
|
交互流程如下:
- 准备阶段:用户打开网页,看到侧边栏的 “文档上传” 和主界面的聊天区域;
- 上传文档:用户在侧边栏选择 1 个或多个文档(PDF/DOCX 等),点击上传,系统显示 “正在处理文档…”,完成后提示 “处理成功”;
- 提问交互:用户在底部输入框提问(如 “公司的发展历程?”),点击发送;
- 流式回答:系统显示 “思考中”,并开始逐字 / 逐句显示回答(流式输出),同时将用户问题和助手回答保存到聊天历史;
- 重置操作:若用户想切换文档,可点击侧边栏 “清空知识库”,系统删除所有文档和聊天历史,恢复初始状态。
4.6 运行测试
-
确保
.env文件已正确配置 API 密钥 -
在项目根目录下,打开终端执行命令:
1 2cd simple_rag_assistant streamlit run main.py
系统将启动 Web 服务,默认地址为 http://localhost:8501
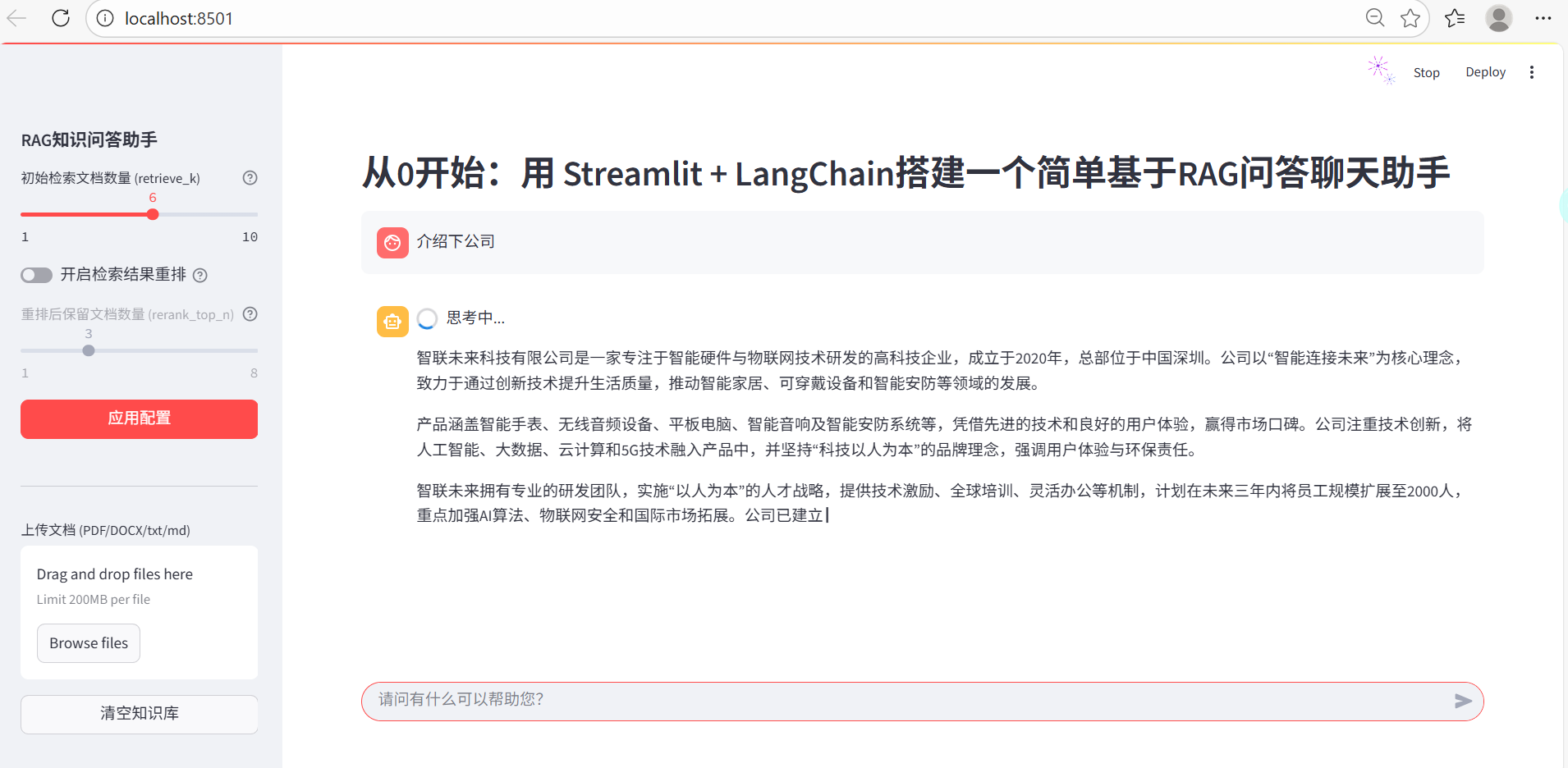
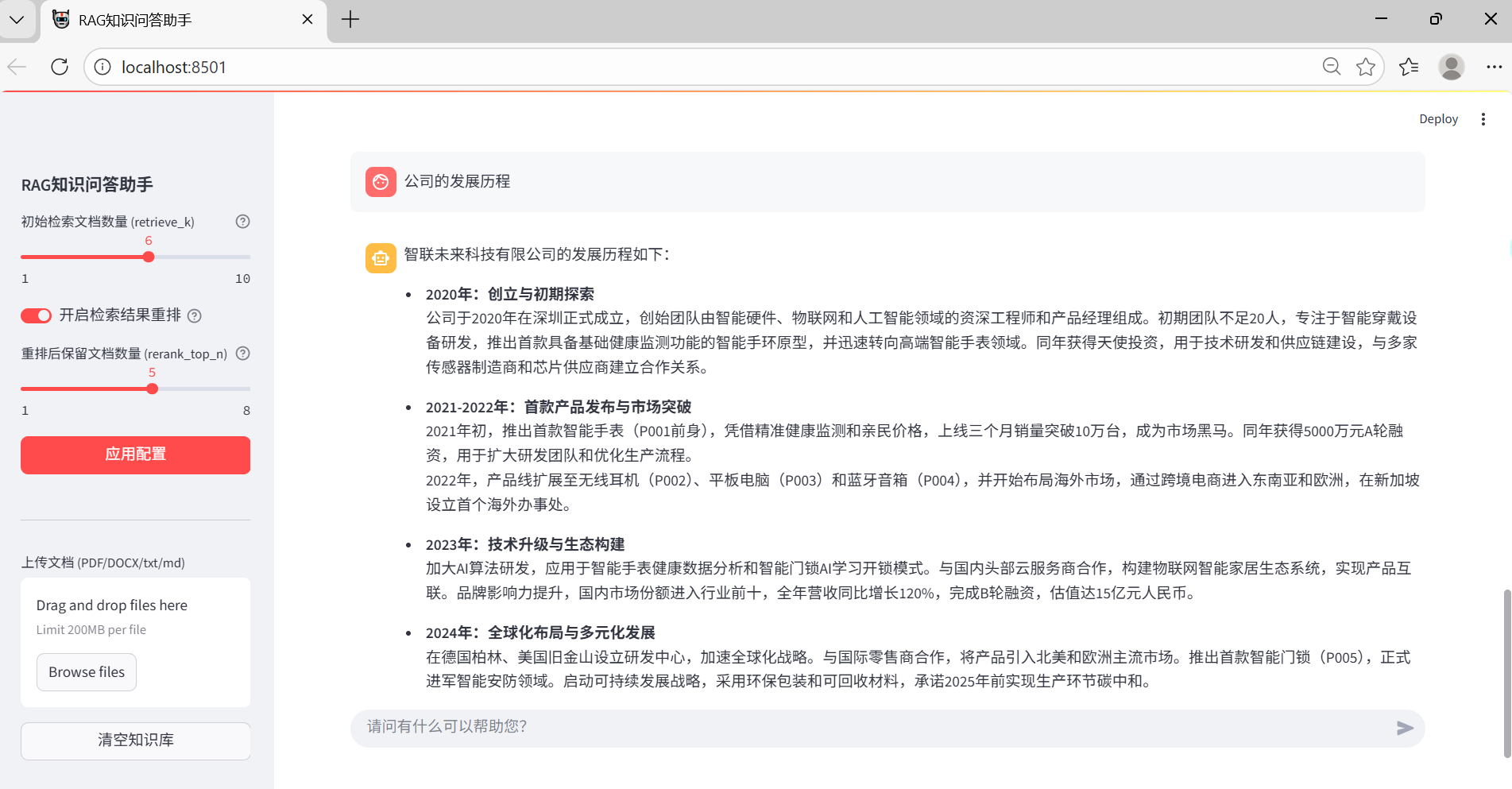
-
浏览器会自动打开界面,使用流程:
- 在侧边栏上传文档(支持多文件)。
- 等待文档处理完成(会显示处理成功提示)。
- 在底部输入框提问,助手会基于上传的文档内容回答。
完整代码位于项目根目录下:practice_cases/simple_rag_assistant
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
4.7 总结
本项目构建了一个功能完整的基础 RAG 问答系统,采用模块化设计保证了代码的可维护性和可扩展性。你可以在此基础上,进一步拓展核心能力与使用体验,如:
- 增加更多文档格式支持(如 PPT、Excel)和多模态识别。
- 实现文档分段预览和定位。
- 添加用户认证和权限管理。
- 优化检索策略,实现更精准的内容匹配与高效召回。
- 增加模型选择功能,允许用户切换不同的 LLM。
通过该项目,你将掌握 RAG 技术的核心原理与工程化实现方法,为后续搭建更复杂的智能检索增强生成(RAG)应用奠定技术基础。