ReAct 原理、架构与代码实现
1 介绍
传统大语言模型(LLM)在处理复杂任务时,还面临着诸多局限性:比如只能进行静态推理(训练完成后内部知识固定),无法根据新情况动态调整;它们常常编造不存在的事实(称为幻觉),如描述一款从未发布的手机型号;在需要多步骤推理的任务中,容易在中间环节出错;更重要的是缺乏与外部环境的交互能力,它们像被关在信息孤岛上,无法与计算器、数据库等外部工具交互,在需要实时信息或工具辅助的复杂任务中表现不佳。而 ReAct 模式的出现,正是为了解决这些问题。
ReAct 是一种结合 “推理(Reasoning)” 与 “行动(Acting)” 的设计模式,源自 2022 年10月 Google 团队的论文《ReAct: Synergizing Reasoning and Acting in Language Models》(论文地址:https://arxiv.org/pdf/2210.03629),一种通过语言模型将推理与行动相结合进行循环迭代,逐步推进问题解决的范式,旨在解决传统 LLM 在复杂任务中存在的静态推理、易幻觉、缺乏外部交互等局限。这种模式在智能体中占有重要地位。
2 核心思想
ReAct的核心思想源于人类解决问题的过程,本质上是一场 “思考 - 行动 - 反馈” 的认知闭环:人类在解决问题时,通常会进行“内心独白”(reasoning)并结合与环境的互动(acting)来逐步逼近目标 。就如周末计划出游时,你会先琢磨 “得看看天气怎么样”(想办法),然后点开天气软件查一查(动手做),发现 “周六要下雨”(看到结果),接着就改主意去看电影了(又开始新一轮琢磨)。
ReAct的核心思路是模拟人类 “思考 - 行动 - 反馈” 的认知闭环,成功实现了将语言模型推理能力与外部工具行动能力的有机结合,显著提升了在复杂任务中的问题解决效率与实际落地能力。具体来说,ReAct 模式通过 “思考(Thought)- 行动(Action)- 观察(Observation)” 的迭代循环机制运作:接收用户任务后,大语言模型生成思考过程,规划下一步行动;接着执行行动,调用工具接口与外部环境交互;然后获取观察结果,即工具返回的信息;最后更新上下文,将任务、思考、行动、观察等完整轨迹存储起来,作为下一轮循环的输入,不断循环迭代,直到完成任务或达到最大迭代次数。
其中核心是推理和行动之间产生强的协同效应:推理轨迹使模型能够进行动态推导、跟踪和调整行动计划,而行动则使模型能够与外部环境资源交互以收集额外信息,进而影响并优化推理决策,通过与环境的持续互动迭代来逐步推进任务的完成。其优势显著,不仅能提升复杂任务的解决能力,通过外部工具补充实时信息解决知识过时问题;还能增强可解释性,显式的 “思考轨迹” 让决策过程透明化,增强可信度;同时具有通用性,适用于知识问答、交互决策、工具调用等多种场景,在智能体开发中占据核心地位。
3 与传统模式的对比
在ReAct 没有出现之前,研究者大都是将推理(Reasoning) 和 行动(Act) 分开来研究,如仅推理(eg:Chain-of-Thought、Tree-of-Thought)、仅行动(eg:WebGPT),它们的对比如下:
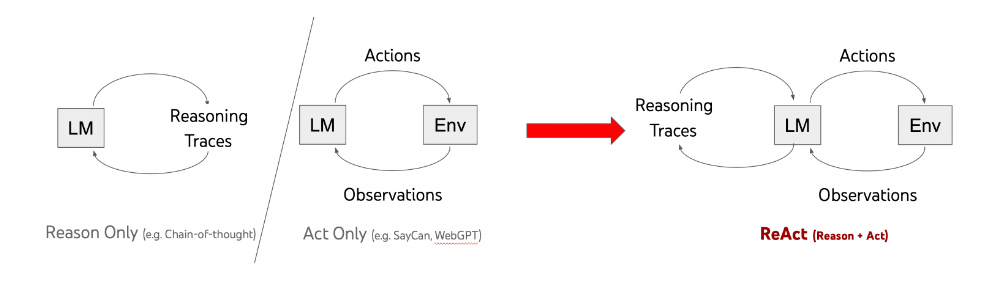
- **思维链(Chain-of-Thought、COT):**是一种让模型生成中间推理步骤的技术,但它是一个静态的黑箱过程。模型仅使用内部表示生成思考,不与外部世界交互,这限制了其在反应性推理或知识更新方面的能力,容易导致事实幻觉和错误传播。
- **思维树(Tree-of-Thoughts、TOT):**允许模型在决策过程中探索多个可能的路径,类似于树状搜索。与 ReAct 相比,ToT 更注重探索不同的解决方案路径,而 ReAct 更强调思考与行动的交互循环。
- 纯行动模式:只执行动作而不生成显式的思考步骤,就像没有大脑的执行者,只能机械地按预设指令操作(如 WebGPT 与互联网交互回答问题的方式),无法根据新情况调整策略。
- ReAct 模式:ReAct 则结合了思考和行动的优势:思考步骤帮助模型归纳、跟踪和更新行动计划,处理异常情况;而行动允许模型与外部资源(如知识库或环境)交互,收集额外信息。这种协同作用使 ReAct 在多个基准测试中表现出色。
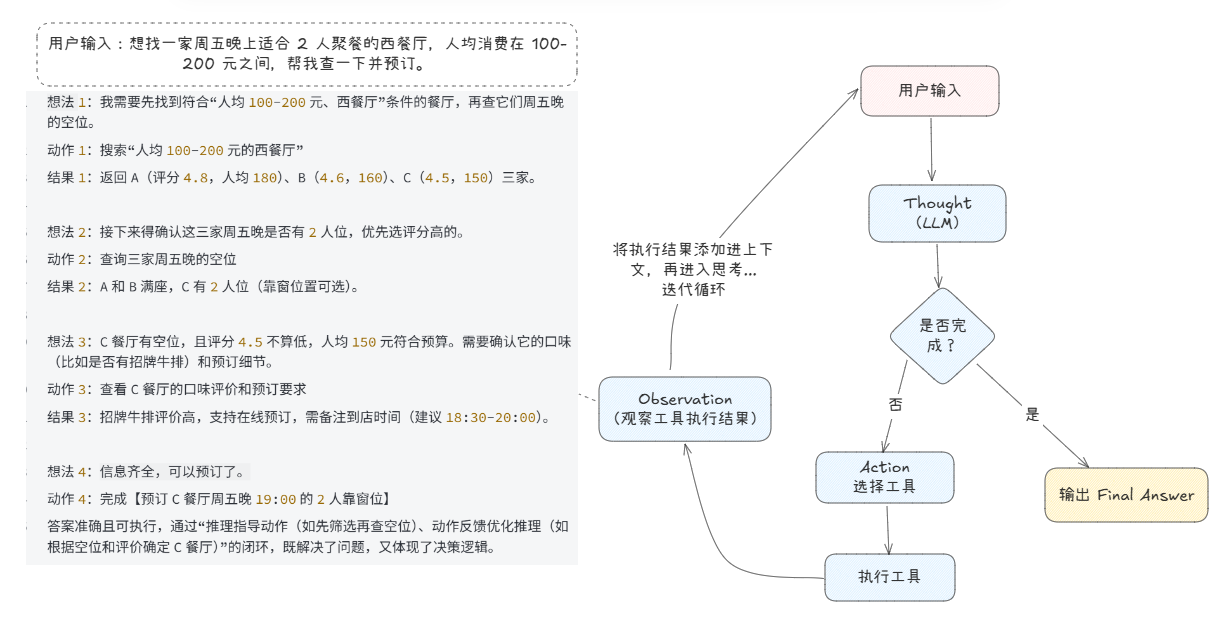
为了更好的了解它们之间的区别,我们以 “查询并预订周五晚上的餐厅” 为例,按不同模式的交互来说明,示例提示问题是 “想找一家周五晚上适合 2 人聚餐的西餐厅,人均消费在 100-200 元之间,帮我查一下并预订。”
1
2
3
4
5
|
提示:
解决这个问题,按人类的思路是:
1. 先筛选符合“西餐厅、人均100-200元、周五晚可预订2人位”条件的餐厅;
2. 查看餐厅评分、口味评价等信息,缩小选择范围;
3. 确定目标餐厅后,完成预订并确认细节(时间、座位偏好等)。
|
- 仅用思维链(Chain-of-Thought、COT)提示。得到结果:
1
2
3
|
想法:首先得找人均100-200元的西餐厅,然后看周五晚上有没有2人的位置。应该选评分高一点的,口味好的。可能需要查一下附近的店。
答案:可以选附近的几家西餐厅,预订周五晚上的位置。
答案流于形式,虽有推理逻辑,但未结合实际信息(如具体餐厅、空位情况),无法落地执行,相当于“只说不做”。
|
- 仅用思维树(Tree-of-Thoughts、TOT)提示。得到结果:
1
2
3
|
想法:分几种情况考虑:方案一,若A餐厅有空位,就订A(评分4.8,人均180元);方案二,若A满了,选B餐厅(评分4.6,人均160元);方案三,若前两家都满了,换C餐厅(评分4.5,人均150元)。但不确定这几家周五是否有空位。
答案:可能订A、B或C餐厅,需看实际空位情况。
答案停留在假设层面,虽探索了多路径,但因未验证“餐厅是否有空位”这一关键信息,无法给出确定结论,属于“空想式规划”。
|
1
2
3
4
5
6
7
8
|
动作1:搜索“人均100-200元的西餐厅”
结果1:返回A、B、C三家餐厅信息
动作2:查询这三家周五晚的空位
结果2:A和B满座,C有2人位
动作3:完成【预订C餐厅】
答案虽有结果,但缺乏推理过程。未解释“为何选C(如评分、口味)”,也未确认预订细节(如到店时间、座位偏好),属于“盲目执行”。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
思考1:我需要先找到符合“人均100-200元、西餐厅”条件的餐厅,再查它们周五晚的空位。
动作1:搜索“人均100-200元的西餐厅”
结果1:返回A(评分4.8,人均180)、B(4.6,160)、C(4.5,150)三家。
思考2:接下来得确认这三家周五晚是否有2人位,优先选评分高的。
动作2:查询三家周五晚的空位
结果2:A和B满座,C有2人位(靠窗位置可选)。
思考3:C餐厅有空位,且评分4.5不算低,人均150元符合预算。需要确认它的口味(比如是否有招牌牛排)和预订细节。
动作3:查看C餐厅的口味评价和预订要求
结果3:招牌牛排评价高,支持在线预订,需备注到店时间(建议18:30-20:00)。
思考4:信息齐全,可以预订了。
动作4:完成【预订C餐厅周五晚19:00的2人靠窗位】
答案准确且可执行,通过“推理指导动作(如先筛选再查空位)、动作反馈优化推理(如根据空位和评价确定C餐厅)”的闭环,既解决了问题,又体现了决策逻辑。
|
通过这个示例可见,ReAct 模式的核心价值在于:用模型推理明确思考过程 “为什么这么做”,用行动验证 “能不能做”,用反馈优化 “怎么做”,完美复刻了人类 “思考 - 行动 - 反馈” 的解决问题模式,既避免了 “空想不落地”,又杜绝了 “盲目乱执行”。
ReAct 模式相比传统方法具有多方面的优势:
- 减少幻觉问题:通过与外部环境交互,ReAct 能够验证假设并获取实时信息,显著降低模型 “幻觉”(生成不准确信息)的风险。
- 提高问题解决能力:在需要多步骤决策和信息检索的任务中,ReAct 表现出色,例如问答、事实核查和交互式决策等领域。
- 增强可解释性:ReAct 生成的推理轨迹提供了透明的决策过程,使得模型的行为更易于理解和信任。
- 适应性强:能够在不同领域和任务间灵活应用,只需调整可用工具集和提示策略。
- 效率提升:最新研究显示,通过优化策略,可实现高达 34% 的运行时间减少,同时保持或提高准确性。
4 工作流程
ReAct 的工作机制可以概括为一个循环过程 “思考(Thought)→ 行动(Action)→ 观察(Observation)”,简称 TAO 循环,如下图所示:
主要包含以下几个关键步骤:
- 接收输入:代理接收用户的初始查询或任务描述。代理根据预设好的 ReAct 提示词模板(格式为Quesion->Thought->Action->Observation)和用户的问题合并,构建上下文提示词发送给大模型。
- 生成思考:LLM 进行思考,分析当前上下文(包含任务和历史交互记录),生成解决问题所需的推理步骤和规划下一步的行动。思考应该明确下一步行动的理由。LLM 生成的行动是标准化的工具调用指令,格式必须严格规范,以便系统解析,通常行动指令包含工具名称和参数,采用:
Action: 工具名称(参数键=参数值, ...)。例如调用计算器时:Action: calculator(expression=3.14*5^2)。若模型思考已足够生成最终答案,则输出行动为Finish,表示已完成任务,并输出最终答案。
- 执行行动:代理解析大模型生成的响应结果,判断输出的Action 是不是 Finish,如果是Finish则表示已经完成任务,直接返回最终答案响应给用户;否则解析出需要执行的工具名称及其参数信息,并调用相应的工具执行,如执行代码、查询数据库、调用 API或执行计算等。
- 获取观察:代理接收行动的结果,即观察值。这一步是检验我们的行动是否有效,是否接近了问题的答案。
- 更新上下文:代理将新的观察结果存入到上下文中(提示词中),形成新的状态,作为下一轮思考的依据。
- 重复循环:代理根据新的状态继续生成思考和执行行动,直到达到终止条件(即任务完成或达到最大迭代次数)。
这种循环结构使得代理能够在 “思考 - 行动 - 观察” 的闭环中不断调整策略,逐步逼近最优解。
5 应用场景
ReAct 模式在多个领域展现出巨大潜力:
- 信息检索与问答系统:如 HotpotQA 等复杂问答任务,ReAct 能够通过多步搜索获取准确答案。
- 交互式决策系统:如在 ALFWorld 和 WebShop 等环境中,ReAct 能够完成复杂的任务序列,成功率显著高于传统方法。
- 智能客服与对话系统:通过结合推理和工具调用,ReAct 可以提供更准确、更个性化的客户支持。
- 专业领域应用:如医疗诊断、法律分析和金融决策等需要专业知识和外部数据支持的领域。
6 代码实现
6.1 架构设计
要将 ReAct 的设计思想落地,实现 “思考 - 行动 - 观察” 的循环,关键是构建一套分工明确且协同工作的架构。其核心组成如下:
-
大语言模型(LLM):智能体的 “大脑”,负责生成思考过程和行动指令,推理能力直接决定智能体表现。**注意:**引导模型生成思考过程和行动指令是由预设好的 ReAct 提示词模板设定的。
-
工具接口(Tools):智能体的 “手脚”,是与外部环境交互的桥梁,如执行代码、查询数据库、调用 API或执行计算等。工具接口需要统一的调用规范,通常要求行动指令包含工具名称和参数,例如:Action: search("2025人工智能法案", "en")
-
上下文管理器(Context):“记忆中枢”,存储完整交互轨迹,包括原始任务、思考记录、行动及观察结果,作为 prompt 输入 LLM,确保智能体能回顾进程、把握当前状态。
-
决策控制器:负责判断何时终止循环(如已经得到最终答案),何时需要继续迭代;同时处理异常情况,比如工具调用失败时指令 LLM 重试,或在超时情况下强制结束并返回当前结果。
6.2 执行流程
各组件是如何交互协作来共同处理任务的呢?如下时序图展示了详细的步骤。
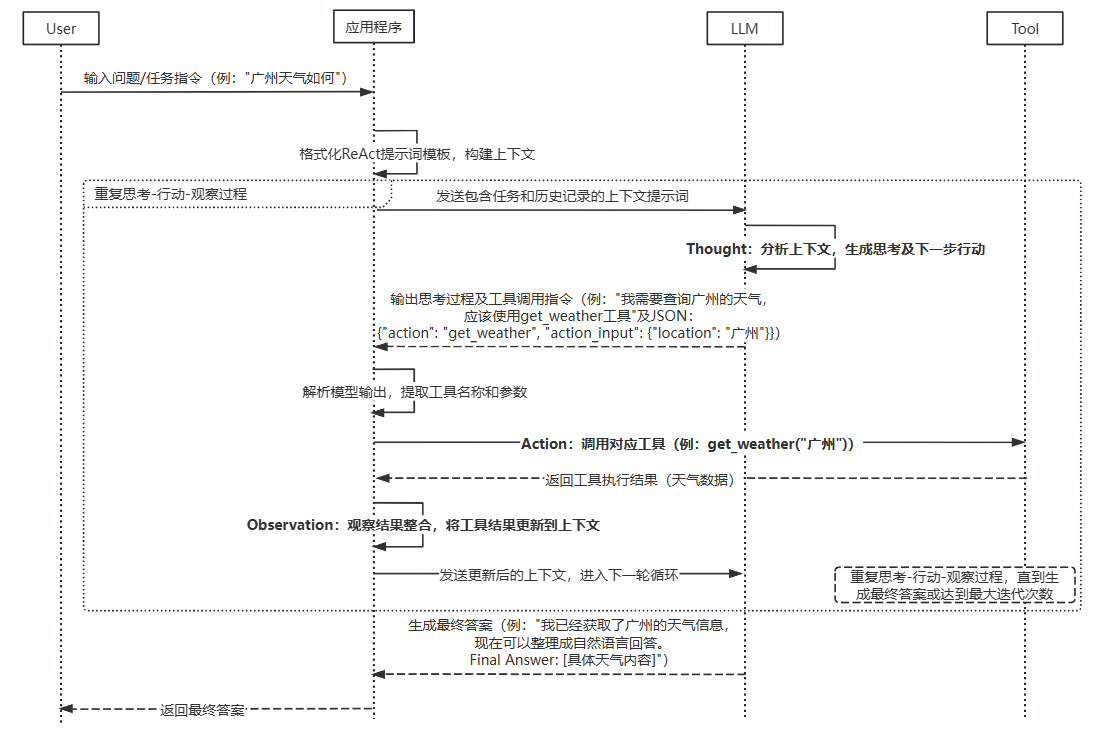
- 任务接收与初始化
- 接收用户输入的问题或任务指令,格式化 ReAct 提示词模板,构建上下文提示词发送给大模型。列如:用户问题 “广州天气如何”。
- 思考生成(Thought)
- LLM 进行思考,分析当前上下文(包含任务和历史交互记录),生成解决问题所需的思考步骤和下一步的行动。
- 示例:AI输出 “我需要查询广州的天气,应该使用 get_weather 工具”,工具调用的 JSON:
{"action": "get_weather", "action_input": {"location": "广州"}}
- 行动决策与执行(Action)
- 解析模型输出,提取出工具名称和参数,调用对应工具获取结果。
- 示例:
调用get_weather(“广州”),获取天气数据
- 观察结果整合(Observation)
- 接收工具返回的结果,更新到上下文,作为下一轮思考的依据。
- 循环与终止
- 重复思考 - 行动 - 观察过程,直到模型判断已获取足够信息,生成最终答案。
- 生成最终答案,格式通常为:
我已经获取了广州的天气信息,现在可以整理成自然语言回答。Final Answer: 地球直径约为月球的3.67倍
6.3 ReAct模式实现方案
目前,许多大语言模型(LLM)支持 Function Calling 机制,可实现高效的工具调用及与外部 API 的交互。像 GPT-4、通义千问 Plus 等支持该机制的模型,能自动判断何时需要调用函数,并以 JSON 格式输出包含函数名和所需参数的结构化数据。
不过,由于 ReAct 模式的论文发表于 2022 年 10 月,而 Function Calling 机制最早由 OpenAI 在 2023 年 6 月提出,因此早期的 ReAct 代码实现需通过编写较复杂的提示词,要求模型返回特定格式的响应。但并非所有 LLM 都支持 Function Calling,对于不支持该机制的模型,仍需依靠提示词来实现 ReAct 模式。
此外,LangGrath作为强大的大模型应用开发框架,也有许多的开发者使用。鉴于此,这里列出三种 ReAct 模式的代码实现方案:
6.4 实现方案一:基于提示词的ReAct模式实现
1、准备工作
- Python 3.11+
- 安装必要的库:
pip install openai requests python-dotenv
- 一个可用的大语言模型接口(这里使用的是 “qwen”,也可替换为其它模型)
- 配置虚拟环境(使用如conda、venv等,推荐但可选)
2、设置API Key
创建.env,配置模型的API访问密钥,这里使用千问模型,需配置QWEN_API_KEY、QWEN_BASE_URL。
1
2
3
4
5
|
# 千问模型接口访问key
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
QWEN_API_KEY="sk-*******"
# 千问模型接口访问地址
QWEN_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
|
3、创建文件,导入依赖
创建react_original.py文件,导入相关依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import json
import re
from typing import Optional, Dict
import requests
import urllib.parse
# 加载环境变量
from dotenv import load_dotenv
from call_llm.call_llm import initialize_model_client #基于openai SDK的模型调用客户端
load_dotenv()
|
4、准备Prompt模板
实现ReAct模式的关键是设计一个清晰的Prompt模板,该提示模板是给模型的 “操作手册”,规定了思考和调用工具的规则。示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# react 提示词模板
REACT_PROMPT_FORMAT = """
Answer the following questions as best you can. You have access to the following tools:
{tools}
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: {tool_names}
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{{{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}}}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
"""
|
提示词模板包含以下几个元素:
- 告诉模型有哪些工具可用(
{tools}会被替换为实际工具列表)
- 如何调用这些工具,严格规定工具调用格式(用特定的 JSON 格式)
- 强制要求遵循 “思考→行动→观察” 的流程
- 明确最终答案的格式(必须以 “Final Answer:” 开头)
定义工具(Tools)的schema是为了让模型知道有哪些工具可用,使模型能准确判断何时及如何使用工具,生成准确的工具调用指令。包含函数名称、功能描述,清晰的适用场景及参数要求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# 工具定义schema
tool_definition = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定地点的天气信息。参数为地点名称,例如:北京、上海",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "location"}
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "用于数学计算,输入应为数学表达式,例如'3+5*2'或'(4+6)/2'",
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "数学表达式"}
},
"required": ["expression"],
},
},
}
]
|
工具的具体实现
实现工具的具体功能,这里定义了两个函数:
get_weather函数:通过访问天气 API 获取指定地点的天气calculate函数:计算数学表达式的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# 实现获取天气
def get_weather(location: str) -> str:
"""获取指定地点的天气信息。参数为地点名称,例如:北京、上海"""
url = "http://weather.cma.cn/api/autocomplete?q=" + urllib.parse.quote(location)
response = requests.get(url)
data = response.json()
if data["code"] != 0:
return "没找到该位置的信息"
location_code = ""
for item in data["data"]:
str_array = item.split("|")
if (
str_array[1] == location
or str_array[1] + "市" == location
or str_array[2] == location
):
location_code = str_array[0]
break
if location_code == "":
return "没找到该位置的信息"
url = f"http://weather.cma.cn/api/now/{location_code}"
return requests.get(url).text
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
print(f"[执行计算] {expression}")
# 实际应用中应使用更安全的计算库
result = eval(expression)
return f"计算结果: {expression} = {result}"
except Exception as e:
return f"计算错误: {str(e)}"
|
初始化工具及统一工具调用
1
2
3
4
5
6
7
8
9
10
11
12
|
# 初始化工具
tools = {
"get_weather": get_weather,
"calculate": calculate
}
# 实现统一工具调用,根据名称找到并调用对应的工具
def invoke_tool(toolName: str, toolParameters) -> str:
"""工具调用"""
if toolName not in tools:
return f"函数{toolName}未定义"
return tools[toolName](**toolParameters)
|
6、生成系统提示词
根据之前准备的 ReAct Prompt模板,填充可用工具定义,生成完整的系统提示词。
1
2
3
4
|
def get_system_prompt():
tool_strings = "\n".join([json.dumps(tool["function"], ensure_ascii=False) for tool in tool_definition])
tool_names = ", ".join([tool["function"]["name"] for tool in tool_definition])
return REACT_PROMPT_FORMAT.format(tools=tool_strings, tool_names=tool_names)
|
7、实现ReAct 主流程逻辑
ReAct 模式的核心逻辑,主导 “思考→行动→观察” 的闭环循环,直至达成任务目标或达到最大迭代次数。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
# 系统信息
system_msg = {"role": "system", "content": get_system_prompt()}
maxIter = 5 # 最大迭代次数
agent_scratchpad = "" # 历史思考、行动、观察记录
# 获取千问模型客户端
client = initialize_model_client()
for iter_seq in range(1, maxIter + 1):
print(f"\n\n\n>>> 迭代次数: {iter_seq}")
# 构建消息列表
messages = [
system_msg,
{"role": "user", "content": f"Question: {query}\n\nhistory:\n{agent_scratchpad}"}
]
# 向LLM发起请求
chat_completion = client.chat.completions.create(
......
)
print(f">>> LLM响应:\n{content}")
# 检查是否有最终答案,有则直接返回答案
final_answer_match = re.search(r"Final Answer:\s*(.*)", content, re.DOTALL)
if final_answer_match:
final_answer = final_answer_match.group(1)
print(f"\n>>> 最终答案: {final_answer}")
return
# 解析提取工具调用信息
tool_call = parse_action(content)
if not tool_call:
result = "错误: 无法从响应中提取工具调用信息"
print(f">>> {result}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: {result}\n"
continue
try:
tool_name = tool_call["tool_name"]
tool_parameters = tool_call["input"]
# 调用工具并获取结果
result = invoke_tool(tool_name, tool_parameters)
print(f">>> 工具返回结果: {result}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: {result}\n"
except Exception as e:
print(f">>> 错误: 工具调用失败 - {str(e)}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: 错误: 工具调用失败 - {str(e)}\n"
print("\n>>> 迭代次数达到上限或发生错误,无法生成最终答案")
|
实现基于 ReAct 模式的 Agent 执行流程,核心逻辑如下:
- 初始化系统信息(系统提示、最大迭代次数、历史记录存储)和模型客户端。
- 在最大迭代次数内循环执行:
- 构建包含系统提示、用户问题和历史记录的消息。
- 调用大语言模型(千问或 GPT)获取思考结果。
- 检查是否生成最终答案(响应以
Final Answer:开头),若有则返回,若没有说明还有行动(工具调用)要完成。
- 否则解析模型响应中的工具调用指令。
- 执行相应工具并获取结果(即观察结果),更新历史记录。
- 进入下一轮的循环。
- 若达到最大迭代次数仍无结果,则提示无法完成。
整个流程通过循环实现 “思考→行动→观察” 的闭环,历史记录 (agent_scratchpad) 不断累积以提供上下文,确保 Agent 能基于之前的交互继续推理,直至达成任务目标或达到最大迭代次数。
8、完整代码
完整代码位于项目根目录下:cognitive_pattern/react/react_original.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
|
import json
import os
import re
from typing import Optional, Dict
import requests
import urllib.parse
# 加载环境变量
from dotenv import load_dotenv
from openai import OpenAI
def initialize_model_client() -> OpenAI:
"""
获取模型调用客户端,使用openai SDK,支持所有兼容openai接口的模型服务,默认使用千问模型
Returns:
OpenAI客户端实例
"""
# 获取千问API密钥
qwen_api_key = os.getenv("QWEN_API_KEY")
if not qwen_api_key:
raise ValueError(f"缺少{qwen_api_key}环境变量")
# 获取千问请求端口URL
qwen_base_url = os.getenv("QWEN_BASE_URL")
client = OpenAI(
# 配置请求密钥:api_key,这里使用千问模型,请用百炼API Key将下行替换。
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
api_key=qwen_api_key,
base_url=qwen_base_url,
)
return client
load_dotenv()
# react 提示词模板
REACT_PROMPT_FORMAT = """
Answer the following questions as best you can. You have access to the following tools:
{tools}
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: {tool_names}
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{{{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}}}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
"""
# 工具定义
tool_definition = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定地点的天气信息。参数为地点名称,例如:北京、上海",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "location"}
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "用于数学计算,输入应为数学表达式,例如'3+5*2'或'(4+6)/2'",
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "数学表达式"}
},
"required": ["expression"],
},
},
}
]
# 实现获取天气
def get_weather(location: str) -> str:
"""获取指定地点的天气信息。参数为地点名称,例如:北京、上海"""
url = "http://weather.cma.cn/api/autocomplete?q=" + urllib.parse.quote(location)
response = requests.get(url)
data = response.json()
if data["code"] != 0:
return "没找到该位置的信息"
location_code = ""
for item in data["data"]:
str_array = item.split("|")
if (
str_array[1] == location
or str_array[1] + "市" == location
or str_array[2] == location
):
location_code = str_array[0]
break
if location_code == "":
return "没找到该位置的信息"
url = f"http://weather.cma.cn/api/now/{location_code}"
return requests.get(url).text
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
print(f"[执行计算] {expression}")
# 实际应用中应使用更安全的计算库
result = eval(expression)
return f"计算结果: {expression} = {result}"
except Exception as e:
return f"计算错误: {str(e)}"
# 初始化工具
tools = {
"get_weather": get_weather,
"calculate": calculate
}
# 工具调用
def invoke_tool(toolName: str, toolParameters) -> str:
"""工具调用"""
if toolName not in tools:
return f"函数{toolName}未定义"
return tools[toolName](**toolParameters)
# 系统提示词
def get_system_prompt():
tool_strings = "\n".join([json.dumps(tool["function"], ensure_ascii=False) for tool in tool_definition])
tool_names = ", ".join([tool["function"]["name"] for tool in tool_definition])
return REACT_PROMPT_FORMAT.format(tools=tool_strings, tool_names=tool_names)
# 解析提取调用工具及其参数
def parse_action(text: str) -> Optional[Dict[str, str]]:
"""解析模型输出,提取工具调用信息"""
try:
# 查找格式为:
# Action:
# ```
# {"action": "...", "action_input": {...}}
# ```
action_pattern = re.compile(r"\nAction:\n`{3}(?:json)?\n(.*?)`{3}.*?$", re.DOTALL)
action_match = action_pattern.search(text)
if action_match:
tool_call = json.loads(action_match.group(1))
return {
"tool_name": tool_call.get("action"),
"input": tool_call.get("action_input", {})
}
return None
except json.JSONDecodeError as e:
print(f"错误: 解析工具调用信息失败 - {str(e)}")
return None
def run(query: str):
# 系统信息
system_msg = {"role": "system", "content": get_system_prompt()}
print(f"\n【系统】:\n{system_msg['content']}")
print(f"\n【用户】:\n{query}")
maxIter = 5 # 最大迭代次数
agent_scratchpad = "" # 历史思考、行动、观察记录
# 获取千问模型客户端
client = initialize_model_client()
for iter_seq in range(1, maxIter + 1):
print(f"\n\n\n>>> 迭代次数: {iter_seq}")
# 构建消息列表
messages = [
system_msg,
{"role": "user", "content": f"Question: {query}\n\nhistory:\n{agent_scratchpad}"}
]
# 向LLM发起请求
chat_completion = client.chat.completions.create(
messages=messages,
model="qwen-plus-latest",
# model="gpt-3.5-turbo", # 使用早期的openai模型测试
stop="Observation:",
timeout=30
)
content = chat_completion.choices[0].message.content
if not content:
print(">>> 错误: LLM返回空内容")
break
print(f">>> LLM响应:\n{content}")
# 检查是否有最终答案
final_answer_match = re.search(r"Final Answer:\s*(.*)", content, re.DOTALL)
if final_answer_match:
final_answer = final_answer_match.group(1)
print(f"\n>>> 最终答案: {final_answer}")
return
# 解析提取工具调用信息
tool_call = parse_action(content)
if not tool_call:
result = "错误: 无法从响应中提取工具调用信息"
print(f">>> {result}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: {result}\n"
continue
# 执行工具
try:
tool_name = tool_call["tool_name"]
tool_parameters = tool_call["input"]
print(f">>> 调用工具: {tool_name}")
print(f">>> 工具参数: {tool_parameters}")
# 调用工具并获取结果
result = invoke_tool(tool_name, tool_parameters)
print(f">>> 工具返回结果: {result}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: {result}\n"
except Exception as e:
print(f">>> 错误: 工具调用失败 - {str(e)}")
# 更新思考过程
agent_scratchpad += f"{content}\nObservation: 错误: 工具调用失败 - {str(e)}\n"
print("\n>>> 迭代次数达到上限或发生错误,无法生成最终答案")
if __name__ == "__main__":
query = "广州天气如何"
# query = "计算223344557799*5599"
run(query)
|
9、运行测试
打开命令行窗口,进入代码文件的目录下(位于项目的cognitive_architecture\react目录)。
执行代码:
1
|
python .\react_original.py
|
运行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
【用户】:
广州天气如何
>>> 迭代次数: 1
>>> LLM响应:
Thought: 我需要获取广州的天气信息
Action:
```
{"action": "get_weather", "action_input": {"location": "广州"}}
```
>>> 调用工具: get_weather
>>> 工具参数: {'location': '广州'}
>>> 工具返回结果: {"msg":"success","code":0,"data":{"location":{"id":"59287","name":"广州","path":"中国, 广东, 广州"},"now":{"precipitation":0.0,"temperature":26.4,"pressure":995.0,"humidity":95.0,"windDirection":"东北风","windDirectionDegree":80.0,"windSpeed":1.1,"windScale":"微风","feelst":31.4},"alarm":[],"jieQi":"","lastUpdate":"2025/08/02 20:45"}}
>>> 迭代次数: 2
>>> LLM响应:
Thought: 我现在知道了广州的天气情况。
Final Answer: 广州当前天气温度为26.4°C,体感温度31.4°C,湿度95%,气压995.0 hPa,风向为东北风,风速1.1 m/s(微风),无降水。天气较闷热,建议注意防暑降温。
>>> 最终答案: 广州当前天气温度为26.4°C,体感温度31.4°C,湿度95%,气压995.0 hPa,风向为东北风,风速1.1 m/s(微风),无降水。天气较闷热,建议注意防暑降温。
Process finished with exit code 0
|
可以看到代理经过思考并调用工具get_weather,结合工具响应结果,最终回复了用户问题广州天气如何的准确答案。
6.5 实现方案一:基于Function Calling的ReAct模式实现
基于Function Calling的ReAct模式实现与基于提示词的实现基本类似,主要有以下两点差异:
-
基于提示词实现模式
-
**提示词编写:**需要在系统提示词中详细定义工具调用的格式,依赖模型理解并遵守格式要求。
-
**响应工具解析:**通过自然语言提示词约束模型输出格式,要求模型在回答中用特定格式(如 ``` 包裹的 JSON)描述要调用的工具和参数。
例如,模型必须输出类似:
1
2
3
4
|
{
"action": "get_weather",
"action_input": {"location": "广州"}
}
|
程序需要通过正则表达式手动解析这段文本,提取工具名称和参数。
-
基于Function Calling 实现模式
- **提示词编写:**无需在提示词中详细描述格式,直接在请求中指定工具定义(
tool_definitions),通过tools参数传递给模型 API。模型会自动生成结构化的工具调用信息(包含在响应的tool_calls字段中),无需手动解析自然语言。
- **响应工具解析:**模型的响应会包含专门的
tool_calls字段,直接返回结构化的工具调用数据(如function.name和function.arguments),程序可直接使用,无需正则匹配。
基于Function Calling的ReAct模式实现的完整代码如下:
完整代码位于项目根目录下:cognitive_pattern/react/react_functioncalling.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
|
import json
import os
import re
from typing import Dict, List
import requests
import urllib.parse
# 加载环境变量
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
def initialize_model_client() -> OpenAI:
"""
获取模型调用客户端,使用openai SDK,支持所有兼容openai接口的模型服务,默认使用千问模型
Returns:
OpenAI客户端实例
"""
# 获取千问API密钥
qwen_api_key = os.getenv("QWEN_API_KEY")
if not qwen_api_key:
raise ValueError(f"缺少{qwen_api_key}环境变量")
# 获取千问请求端口URL
qwen_base_url = os.getenv("QWEN_BASE_URL")
client = OpenAI(
# 配置请求密钥:api_key,这里使用千问模型,请用百炼API Key将下行替换。
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
api_key=qwen_api_key,
base_url=qwen_base_url,
)
return client
# 工具定义 - 符合function calling格式
tool_definitions = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定地点的天气信息。参数为地点名称,例如:北京、上海",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "地点名称,例如:北京、上海"}
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "用于数学计算,输入应为数学表达式,例如'3+5*2'或'(4+6)/2'",
"parameters": {
"type": "object",
"properties": {
"expression": {"type": "string", "description": "数学表达式,例如:1+2*3、(5+8)/2"}
},
"required": ["expression"],
},
},
}
]
# 实现获取天气
def get_weather(location: str) -> str:
"""获取指定地点的天气信息。参数为地点名称,例如:北京、上海"""
url = "http://weather.cma.cn/api/autocomplete?q=" + urllib.parse.quote(location)
response = requests.get(url)
data = response.json()
if data["code"] != 0:
return "没找到该位置的信息"
location_code = ""
for item in data["data"]:
str_array = item.split("|")
if (
str_array[1] == location
or str_array[1] + "市" == location
or str_array[2] == location
):
location_code = str_array[0]
break
if location_code == "":
return "没找到该位置的信息"
url = f"http://weather.cma.cn/api/now/{location_code}"
return requests.get(url).text
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
print(f"[执行计算] {expression}")
# 实际应用中应使用更安全的计算库
result = eval(expression)
return f"计算结果: {expression} = {result}"
except Exception as e:
return f"计算错误: {str(e)}"
# 初始化工具映射
tools = {
"get_weather": get_weather,
"calculate": calculate
}
# 工具调用
def invoke_tool(tool_name: str, tool_parameters) -> str:
"""工具调用"""
if tool_name not in tools:
return f"函数{tool_name}未定义"
return tools[tool_name](**tool_parameters)
# React模式系统提示词
def get_system_prompt():
return "你需要通过思考-行动-观察的循环来回答用户问题。" \
"可以使用提供的工具获取信息。\n" \
"思考过程(Thought):分析问题,决定是否需要调用工具\n" \
"如果需要调用工具,使用指定的函数调用格式(Action)\n" \
"获取工具返回结果后(Observation),继续思考下一步\n" \
"当获得足够信息后,用'Final Answer: '开头给出最终答案。"
def run(query: str):
# 系统信息
system_msg = {"role": "system", "content": get_system_prompt()}
print(f"\n【系统】:\n{system_msg['content']}")
print(f"\n【用户】:\n{query}")
max_iter = 5 # 最大迭代次数
messages: List[Dict] = [system_msg,
{"role": "user", "content": query}]
# 记录React流程的思考过程
react_history = ""
# 获取模型客户端
client = initialize_model_client()
for iter_seq in range(1, max_iter + 1):
print(f"\n\n\n>>> 迭代次数: {iter_seq}")
print(f">>> 当前React历史:\n{react_history}")
# 向LLM发起请求,指定可以调用的工具
chat_completion = client.chat.completions.create(
messages=messages,
model="qwen-plus-latest",
tools=tool_definitions,
tool_choice="auto", # 让模型自动决定是否调用工具
timeout=60
)
response = chat_completion.choices[0].message
content = response.content
#模型响应的调用工具信息
tool_calls = response.tool_calls
print(f">>> LLM响应内容:\n{content}")
# 记录思考过程
react_history += f"Thought: {content}\n"
# 检查是否有最终答案
if content and re.search(r"Final Answer:\s*", content, re.DOTALL):
final_answer = re.sub(r"Final Answer:\s*", "", content, re.DOTALL)
print(f"\n>>> 最终答案: {final_answer}")
return
# 将模型的响应添加到消息历史中
messages.append({
"role": "assistant",
"content": content,
"tool_calls": tool_calls
})
# 如果没有工具调用,说明模型无法回答或需要更多信息
if not tool_calls:
print(">>> 模型没有调用任何工具,也没有给出最终答案")
react_history += "Observation: 无法确定需要调用的工具\n"
continue
# 处理工具调用
for tool_call in tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
print(f">>> 调用工具: {function_name}")
print(f">>> 工具参数: {function_args}")
# 记录工具调用
react_history += f"Action: 调用工具 {function_name},参数 {json.dumps(function_args)}\n"
# 调用工具并获取结果
try:
result = invoke_tool(function_name, function_args)
print(f">>> 工具返回结果: {result}")
react_history += f"Observation: {result}\n"
# 将工具调用结果添加到消息历史中
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": function_name,
"content": result
})
except Exception as e:
error_msg = f"工具调用失败: {str(e)}"
print(f">>> {error_msg}")
react_history += f"Observation: {error_msg}\n"
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": function_name,
"content": error_msg
})
print("\n>>> 迭代次数达到上限或发生错误,无法生成最终答案")
print(f">>> 完整React历史:\n{react_history}")
if __name__ == "__main__":
query = "广州天气如何"
# query = "计算223344557799*5599"
run(query)
|
6.6 实现方案一:基于LangGrath的ReAct模式实现
LangGraph 是 LangChain 生态系统的重要组成部分,专注于构建基于 LLM(大型语言模型)的复杂工作流与 Agent 系统。它以有向图结构为核心来定义工作流,让开发者能够轻松创建动态可控、可灵活扩展的 AI 应用。
简单来说,LangGraph 是一个框架:它底层用图(Graph)结构来规划工作流 —— 把整体任务拆分成一个个「节点(Actors)」,再用「有向边(Edges)」将这些节点串联起来。其中,节点代表具体的执行步骤,既可以封装 LLM 调用、工具函数,也能植入自定义逻辑;而边则负责定义节点之间的流转规则,比如支持根据条件判断下一步走向。通过这种设计,开发者能灵活控制流程的分支与循环,从而实现复杂的多步骤工作流。
LangGraph 关键技术组件:
-
**MessagesState 状态管理机制:**作为 LangGraph 的核心状态模式,采用包含消息列表的 TypedDict 结构,负责统一存储用户输入、模型响应及工具输出。该状态在所有节点间共享,为整个工作流提供了连续且一致的 “记忆” 基础。
-
**节点系统:**是任务执行的基本单元。将每个可执行单元(如 LLM 调用、工具函数或自定义逻辑)抽象为图中的独立节点。节点通过返回更新后的状态(例如新生成的消息),推动状态向前传递。
-
**边连接机制:**定义节点间的转换规则,支持循环构建(如工具调用与智能体决策的往返交互)、设置条件分支(根据不同结果选择下一步路径)以及停止条件(判断流程何时终止),是实现复杂流程控制的关键。
支持三大核心能力:构建循环流程(如工具调用与智能体决策的往返交互)、设置条件分支(根据不同结果选择下一步路径)、设定停止条件(判断流程何时终止),是实现复杂流程控制的关键。
-
**ToolExecutor 工具执行器:**作为连接外部能力的桥梁,它允许在 LangGraph 中直接调用 LangChain 生态的工具,便捷地将 API 接口、计算器等外部函数集成到推理流程中,扩展了系统的实际操作能力。
-
**记忆循环系统:**依托 MessagesState 携带完整对话历史,使智能体能够基于过往交互进行多跳推理(如从历史信息中推导新结论)。这种循环记忆机制是实现复杂决策和上下文连贯的技术基础。
基于LangGrath的ReAct模式的代码实现如下:
1、准备工作
环境配置:
- Python 3.11+
- 安装必要的库:
pip install openai requests python-dotenv langchain langgraph pydantic
- 一个可用的大语言模型接口(这里使用的是 “qwen”,也可替换为其它模型)
- 配置虚拟环境(使用如
conda、venv等,推荐但可选)
设置API Key:
创建.env,配置模型的API访问密钥,这里使用千问模型,需配置QWEN_API_KEY、QWEN_BASE_URL。
1
2
3
4
5
|
# 千问模型接口访问key
# 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
QWEN_API_KEY="sk-*******"
# 千问模型接口访问地址
QWEN_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
|
2、创建文件,导入依赖
创建文件react_langgrath.py,导入相关依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import requests
import urllib.parse
from typing import Annotated, Literal, Optional, Dict, List, Any
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from openai import OpenAI
from pydantic import BaseModel, Field
from langchain.tools import tool
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
|
3、工具函数定义
工具是智能体与外部交互的接口,通过@tool装饰器定义,这里包含天气查询和数学计算两个工具。
(1)天气查询工具 get_weather
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@tool("get_weather", return_direct=False)
def get_weather(location: str) -> str:
"""获取指定地点的天气信息。参数为地点名称,例如:北京、上海"""
try:
# 1. 调用自动补全API获取地点编码(通过气象局API)
url = "http://weather.cma.cn/api/autocomplete?q=" + urllib.parse.quote(location)
response = requests.get(url)
data = response.json()
# 2. 检查API返回状态
if data["code"] != 0:
return "没找到该位置的信息"
# 3. 提取地点编码(匹配地点名称)
location_code = ""
for item in data["data"]:
str_array = item.split("|")
# 匹配规则:精确匹配地点名,或地点名+市,或下级区域名
if (str_array[1] == location or str_array[1] + "市" == location or str_array[2] == location):
location_code = str_array[0]
break
# 4. 若未找到编码,返回错误
if location_code == "":
return "没找到该位置的信息"
# 5. 用地点编码调用实时天气API
url = f"http://weather.cma.cn/api/now/{location_code}"
return requests.get(url).text
except Exception as e:
return f"获取天气信息失败:{str(e)}"
|
功能:通过中国天气网的公开 API 获取指定地点的实时天气。
(2)数学计算工具 calculate
1
2
3
4
5
6
7
8
9
|
@tool("calculate", return_direct=False)
def calculate(expression: str) -> str:
"""计算数学表达式的结果。参数为数学表达式,例如:1+2*3、(5+8)/2"""
try:
# 实际应用中应使用更安全的计算库,如sympy
result = eval(expression)
return f"计算结果: {expression} = {result}"
except Exception as e:
return f"计算错误: {str(e)}"
|
功能:计算数学表达式(如3.14*(5^2))。
注意:使用eval直接执行字符串表达式,存在安全风险(可能执行恶意代码),注释中建议实际应用用sympy等安全库。
4、状态模型定义
状态是智能体在流转过程中保存的数据,用 Pydantic 模型定义:
1
2
3
4
5
|
class State(BaseModel):
# 消息列表:用add_messages注解确保消息可追加(类似对话历史)
messages: Annotated[List[Any], add_messages] = Field(default_factory=list)
# 流程状态标志:是否已完成处理
is_finished: bool = False
|
messages:存储对话历史(用户提问、智能体回复、工具调用结果等),add_messages确保新消息能正确追加到列表。is_finished:控制流程是否结束(True表示可以返回最终答案)
5、智能体节点(Agent Node)
智能体节点是决策核心,负责判断是否需要调用工具,或直接生成答案。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
def agent_node(state: State):
# 初始化LLM(注意:initialize_qwen_llm函数未在代码中定义,需用户实现)
llm = initialize_qwen_llm(
model="qwen-plus-latest", # 模型名称
temperature=0, # 温度参数(0表示确定性输出)
)
# 将工具绑定到LLM,使LLM具备调用工具的能力
llm_with_tools = llm.bind_tools(tools)
# 系统提示:定义智能体的行为准则
system_message = {
"role": "system",
"content": "你拥有调用工具的能力,可以使用工具来回答用户的问题。"
"如果需要调用工具,请使用指定的函数调用格式。"
"如果已经获取了足够的信息,可以直接给出最终答案。"
"请用中文回答用户的问题。"
}
# 构建完整消息列表:系统提示 + 历史对话
messages = [system_message] + state.messages
# 调用LLM,获取响应
response = llm_with_tools.invoke(messages)
# 判断是否需要继续:若LLM未调用工具,则直接返回结果(结束流程)
if not response.tool_calls:
return {
"messages": [response], # 更新消息列表
"is_finished": True # 标记流程结束
}
# 若有工具调用,继续流程
return {
"messages": [response],
"is_finished": False
}
|
- 核心逻辑:LLM 根据对话历史和系统提示,决定是否调用工具(生成
tool_calls)或直接回答。
llm.bind_tools(tools):让 LLM 知晓可用工具的名称、参数和功能描述(从工具函数的文档字符串中提取)。- 返回值:更新后的状态字典(
messages和is_finished)
6、条件判断函数
控制流程走向的核心,决定下一步是调用工具还是结束。
1
2
3
4
5
6
7
8
|
def should_continue(state: State) -> Literal["tools", END]:
if state.is_finished:
return END # 若已完成,返回结束节点
# 检查最后一条消息是否有工具调用
last_message = state.messages[-1] if state.messages else None
if last_message and last_message.tool_calls:
return "tools" # 有工具调用,进入工具节点
return END # 无工具调用,结束流程
|
7、状态图构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
def build_graph(visualize: bool = False):
# 创建状态图(以State为数据模型)
graph = StateGraph(State)
# 初始化工具节点(包装工具函数)
tool_node = ToolNode(tools)
# 向图中添加节点:agent(智能体节点)和tools(工具节点)
graph.add_node("agent", agent_node)
graph.add_node("tools", tool_node)
# 设置入口节点为agent(流程从智能体开始)
graph.set_entry_point("agent")
# 添加条件边:从agent节点根据should_continue的返回值决定下一步
graph.add_conditional_edges(
"agent",
should_continue,
)
# 添加单向边:工具节点执行完成后,回到agent节点继续处理
graph.add_edge("tools", "agent")
# 编译图(生成可执行的工作流)
compiled_graph = graph.compile()
return compiled_graph
|
通过 LangGraph 的状态图 API 构建 “智能体 - 工具” 的循环工作流,支持多轮工具调用。
核心逻辑:
- 定义状态图的节点(agent 和 tools)
- 定义节点间的连接关系:agent→条件判断→tools/END,tools→agent 实现循环。
- 编译图为可执行对象。
8、运行示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def main():
# 构建图(开启可视化)
app = build_graph(visualize=True)
# 测试1:天气查询
query = "广州天气如何"
print(f"【用户查询】: {query}")
# 调用图,传入用户消息
final_state = app.invoke({"messages": [{"role": "user", "content": query}]})
# 输出最终结果(最后一条消息)
print(f"\n【最终答案】:")
print(final_state['messages'][-1].content)
if __name__ == "__main__":
main()
|
完整代码位于项目根目录下:cognitive_pattern/react/react_langgrath.py
打开命令行窗口,进入代码文件的目录下(项目的cognitive_pattern/react目录)。
执行代码:
1
|
python .\react_langgrath.py
|
运行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
【用户查询】: 广州天气如何
【最终答案】:
广州当前天气如下:
- **温度**:26.3℃
- **体感温度**:31.1℃
- **降水量**:6.8mm(有降雨,建议携带雨具)
- **气压**:994.0hPa
- **湿度**:95%(湿度较高,体感闷热)
- **风向**:东南风
- **风速**:1.3m/s(微风)
天气较为潮湿闷热,且有降雨,外出请注意防雨和防暑。
|
9、流式输出
通过流式输出机制,可观察各节点的处理结果,以上代码部分修改为:
1
2
3
4
5
6
7
|
# 流式输出
for output in app.stream({"messages": [{"role": "user", "content": query}]}):
for key, value in output.items():
print(f"输出节点: {key}")
print("_______")
print(value)
print("\n")
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
【用户查询】: 广州天气如何
节点: agent
_______
{'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_0fa38c3ba4db4be8a2767f', 'function': {'arguments': '{"location": "广州"}', 'name': 'get_weather'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 283, 'total_tokens': 302, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'qwen-plus-latest', 'system_fingerprint': None, 'id': 'chatcmpl-b2400c67-2ba7-93b9-a1de-47ee7927f940', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--1242d7b1-f588-4e00-9f77-61d385d9f8f7-0', tool_calls=[{'name': 'get_weather', 'args': {'location': '广州'}, 'id': 'call_0fa38c3ba4db4be8a2767f', 'type': 'tool_call'}], usage_metadata={'input_tokens': 283, 'output_tokens': 19, 'total_tokens': 302, 'input_token_details': {}, 'output_token_details': {}})], 'is_finished': False}
节点: tools
_______
{'messages': [ToolMessage(content='{"msg":"success","code":0,"data":{"location":{"id":"59287","name":"广州","path":"中国, 广东, 广州"},"now":{"precipitation":6.8,"temperature":26.3,"pressure":994.0,"humidity":95.0,"windDirection":"东北风","windDirectionDegree":83.0,"windSpeed":1.5,"windScale":"微风","feelst":30.9},"alarm":[],"jieQi":"","lastUpdate":"2025/08/04 16:55"}}', name='get_weather', id='eff31ebb-fdb3-4fd4-8fe0-95935a07e983', tool_call_id='call_0fa38c3ba4db4be8a2767f')]}
节点: agent
_______
{'messages': [AIMessage(content='广州当前天气情况如下:\n\n- **温度**:26.3°C\n- **体感温度**:30.9°C\n- **降水量**:6.8 mm\n- **气压**:994.0 hPa\n- **湿度**:95%\n- **风向**:东北风(风向角度83.0°)\n- **风速**:1.5 m/s,风力等级为微风\n\n天气较为潮湿,体感较热,建议注意防潮和防暑。最近一次更新时间为2025年8月4日16:55。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 136, 'prompt_tokens': 453, 'total_tokens': 589, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'qwen-plus-latest', 'system_fingerprint': None, 'id': 'chatcmpl-c2f2d34a-e3e8-9ce2-a0d3-cbdbe283a1ea', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--5ab698bd-684a-43a2-939a-b0965de9bfb1-0', usage_metadata={'input_tokens': 453, 'output_tokens': 136, 'total_tokens': 589, 'input_token_details': {}, 'output_token_details': {}})], 'is_finished': True}
Process finished with exit code 0
|
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/react
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/react