Plan-and-execute 原理、架构与代码实现
1. 介绍
为挖掘大型语言模型的推理能力,以解决多步复杂推理任务。研究人员(Wei 等人,2022)提出了少样本思维链(CoT)提示法,通过少量人工构建的分步推理示例,能让大型语言模型明确生成推理步骤,提高解决推理任务的准确率。同时,为了省去提示中人工构建示例的操作,一些研究人员( Kojima 等人,2022)提出零样本思维链(Zero-shot-CoT):通过将目标问题陈述后附加 “让我们一步步思考” 作为输入提示给大型语言模型,出人意料地让大语言模型取得了与少样本思维链提示法相近的性能。但尽管零样本思维链取得了成功,但它仍存在以下三个缺陷:
- 计算错误:中间计算过程出错,导致最终答案偏差。
- 步骤缺失错误:复杂任务中遗漏关键推理环节,逻辑链断裂。
- 语义误解错误:出现对问题的语义理解错误和推理步骤不连贯等其它错误。
为解决零样本思维链的上述缺陷,尤其是 “步骤缺失” 与 “推理不连贯” 问题,由 Lei Wang 等人于 2023 年提出Plan-and-Solve(简称 PS,计划-求解)框架,其论文《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》(论文地址:https://arxiv.org/pdf/2305.04091)于 2023 年 5 月发表。Plan-and-Solve架构作为一种改进零样本思维链( Chain-of-Thought ,CoT)推理的方法。其核心思想是通过引导模型先制定解决问题的计划,再按照计划逐步执行,这一模式显著提高了大模型在复杂任务上的成功率和效率。
2 论文实验
Plan-and-Solve方法本质上是先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行这些子任务,最后合并输出得到结果。在论文中的实验作法是:简单地将零样本思维链中的 “让我们一步步思考” 替换为 “让我们首先理解问题并制定解决计划,然后按照计划一步步解决问题”。如下图所示:

图:GPT-3 在(a)零样本思维链提示、(b)Plan-and-Solve提示、(c)答案提取提示的示例。
上图中,分别演示了三种提示:(a)零样本思维链提示、(b)Plan-and-Solve提示、(c)答案提取提示的示例。零样本思维链(Zero-shot-CoT)通过 “让我们一步步思考” 促使大语言模型生成多步骤推理,但在问题复杂时仍可能产生错误的推理步骤,最终结果错误。与零样本思维链不同,Plan-and-Solve提示首先要求大语言模型通过生成分步计划并执行该计划来设计解题方案,得出最终正确的结果。答案提取提示在Plan-and-Solve提示的基础上,进一步提炼最终答案的格式:因此,答案(阿拉伯数字形式)是60%。
以下是图片文字的中文翻译:
|
|
为解决零样本思维链的计算错误并提升生成的推理步骤质量,我们为 PS 提示法添加了更详细的指令。具体作法是:提示词中增加了 “提取相关变量及其对应数值” 和 “计算中间结果(注意计算和常识)” 的指令。这种提示变体被称为 PS + 提示策略(如下图(b)所示)。
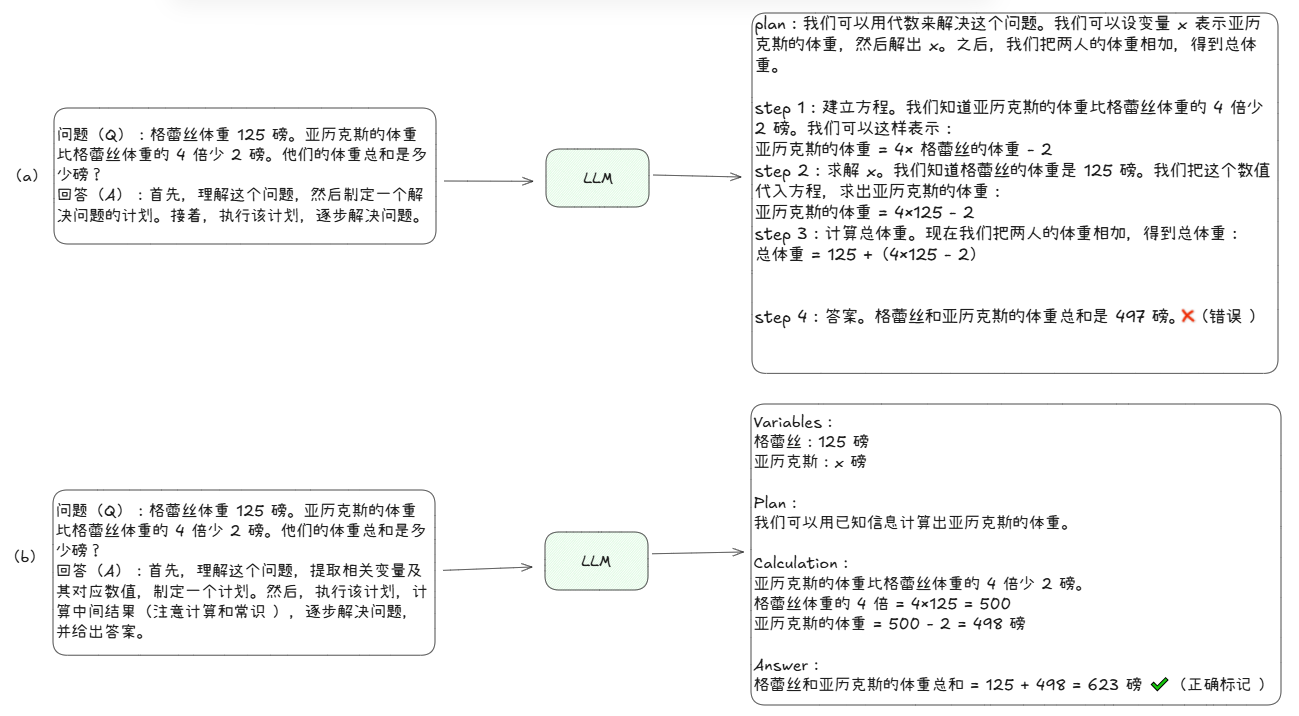
图:(a)Plan-and-Solve提示(PS 提示)和(b)带有更详细指令的Plan-and-Solve提示(PS + 提示)
上图展示了(a)Plan-and-Solve提示(PS 提示)和(b)带有更详细指令的Plan-and-Solve提示(PS + 提示)的示例, PS + 策略仅在提示中增加了 “提取相关变量及其对应数值” 和 “计算中间结果(注意计算和常识)” 的指令,尽管简单,却显著提升了生成的推理过程的质量,并获得正确答案。
论文在三个推理问题类别的十个基准数据集上评估所提出的Plan-and-Solve提示法,包含: 在六个数学推理数据集(包括 AQuA(代数应用题数据集)、GSM8K(小学数学应用题数据集)、MultiArith(需要多步推理和运算的数学应用题数据集)、AddSub(加减法算术应用题数据集)、SingleEq(单方程小学代数应用题的数据集) 和 SVAMP( 4 年级及以下学生的单未知数算术应用题基准));两个常识推理数据集(CommonsenseQA(多项选择题基准数据集)和 StrategyQA(需要多步推理但未给出推理步骤的基准数据集))以及两个符号推理数据集(Last Letter(单词的最后一个字母拼接起来的问题数据集) 和 Coin Flip(关于硬币经过翻转或未翻转后是否仍正面朝上的问题数据集))。
总体而言,实验评估结果表明:
- 零样本 PS 提示法能生成比零样本思维链提示法质量更高的推理过程,因为 PS 提示提供了更详细的指令,引导大型语言模型进行正确推理。
- 零样本 PS + 提示法在所有推理问题和数据集上均大幅优于零样本思维链。此外,尽管 PS + 提示法不需要人工示例,但在算术推理上的性能与少样本思维链提示法相近,在部分数据集上优于少样本人工思维链提示法。
2. 核心思想
2.1 原论文的Plan-and-Solve(规划-求解)提示策略
原论文中提出的Plan-and-Solve(规划-求解)提示策略(简:PS 和 PS + 提示法),是一种新的零样本思维链提示方法,核心是让大语言模型在最终答案前,引导大型语言模型制定解决问题的计划并生成中间推理过程(将整个任务分解为更小的子任务),然后按照计划逐步执行求解,以提高复杂推理任务的准确性和稳定性。其思路通俗来讲,就是让大模型在解决问题时模拟人的过程 “先想后做”,如我们在解决一道复杂的数学题时,不会一下子就写出答案,而是会先在脑海里规划出解题的步骤,比如先分析题目条件、确定使用的公式、分步骤计算等,然后再按照这个规划一步步去计算,最终得到答案。
原论文中提出的Plan-and-Solve(规划-求解)提示策略的实现比较简单,主要是通过构建提示词指令模板,该模板需满足以下两个标准:
- 模板应能促使大型语言模型生成确定计划(子任务)并完成这些子任务。
- 模板应引导大型语言模型更关注计算和中间结果,尽可能确保其正确性。
为满足第一个标准,借鉴零样本思维链。在零样本思维链中,输入指令包括触发指令 “让我们一步步思考”。而零样本 PS 提示法包含 “制定计划” 和 “执行计划” 的指令,因此,提示为 “ 让我们首先理解问题并制定解决计划,然后按照计划一步步解决问题。”
为满足第二个标准,在基于计划的触发语句中扩展更详细的指令。具体来说,添加 “注意计算” 到触发句中,要求大型语言模型尽可能准确地进行计算。为减少因缺失必要推理步骤导致的错误,加入 “提取相关变量及其对应数值”,明确指示大型语言模型不要忽略输入问题中的相关信息。此外,在提示中添加 “计算中间结果”,以增强大型语言模型生成相关重要推理步骤的能力。如提示:“先理解问题,提取相关变量与对应数值,制定计划;再执行计划,计算中间结果(关注计算和常识),逐步解题并给出答案。”
总体来说,这种Plan-and-Solve(规划-求解)提示策略,尽管简单,却显著提升了生成的推理过程的质量。
2.2 改进的计划与求解 (Plan-and-Solve)框架
随着构建基于大语言模型(LLM)的代理(Agent)在复杂任务中的应用不断深化,涌现了许多适配复杂场景的优质设计模式,其中比较典型的是ReAct设计模式,它通过 “思考(Reasoning)→行动(Action)→观察(Observation)” 的循环机制实现动态决策: 先对任务需求进行分析(Reason)并决策出下一步行动,然后执行行动(Action)(如工具调用或信息获取等),再基于行动结果调整策略(Observation),最终逐步逼近目标。
虽然ReAct 对一些任务有效,然而,ReAct 模式存在显著局限 —— 其决策逻辑高度依赖 “局部判断”,每一步仅聚焦单个行动选择,缺乏对任务全局的统筹规划与前瞻性布局。这使得它在复杂任务中易出现两类问题:一是 “路径冗余”,例如处理 “年度经营分析报告生成” 任务时,可能反复调用同一数据工具补充信息;二是 “目标偏移”,比如客服代理在处理用户复合诉求时,因过度关注某一细节问题,偏离了整体需求的解决方向。其在复杂场景下暴露出两个核心缺点:
- LLM 调用效率低:每次执行工具调用前,都需触发一次 LLM 调用以确定行动,导致任务流程中 LLM 调用频次过高,不仅增加时间成本,还提升了资源消耗;
- 全局规划缺失:LLM 仅针对当前子问题进行规划,未对整个任务的完整流程进行系统性推理,易形成次优执行轨迹,难以保障任务最终效果。
通过明确的规划步骤可以克服这两个缺点,借鉴了论文《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》中的思想,在 ReAct 的基础上添加 “全局规划” 能力,形成新的plan-and-execute框架,并涌现了类似的框架项目如Baby-AGI,其核心逻辑可概括为 “先全局规划、后分步执行、再动态调整” 的闭环逻辑:借助 LLM 对任务进行整体规划,生成完整分步计划;再按照计划有序执行,并根据执行反馈(如工具调用结果)对计划进行动态优化,形成 “规划 - 执行 - 反馈 - 调整” 的完整链路。既保留了 ReAct 的灵活性,又弥补了其全局统筹能力的不足。
Plan-and-Execute 的架构由规划器(Planner)、执行器(Executor)、重规划器(Replanner) 三部分组成:
- 规划器(Planner):接收用户需求后,调用 LLM 进行深度拆解与全局规划,生成完整分步计划。
- 执行器(Executor):接收规划器输出的分步计划,按序执行每个子任务。在实现层面,执行器可为具备工具调用能力的独立 Agent— 根据子任务需求自主选择 API 接口、数据检索工具或自动化组件,完成具体操作并返回执行结果(如调用海关数据库获取目标市场关税数据)。
- 重规划器(Replanner):负责根据执行器的实际执行情况和信息反馈来调整计划。
Plan-and-Execute框架是在Plan-and-Solve Prompting框架上的扩展。通过以上这三个部分,形成 “规划→执行→反馈→调整” 的完整循环链路,既保证了任务处理的全局统筹性,又赋予系统应对复杂场景的动态适应能力。
3. 工作流程
Plan-and-Execute(规划 - 执行)框架的工作流程图如下:
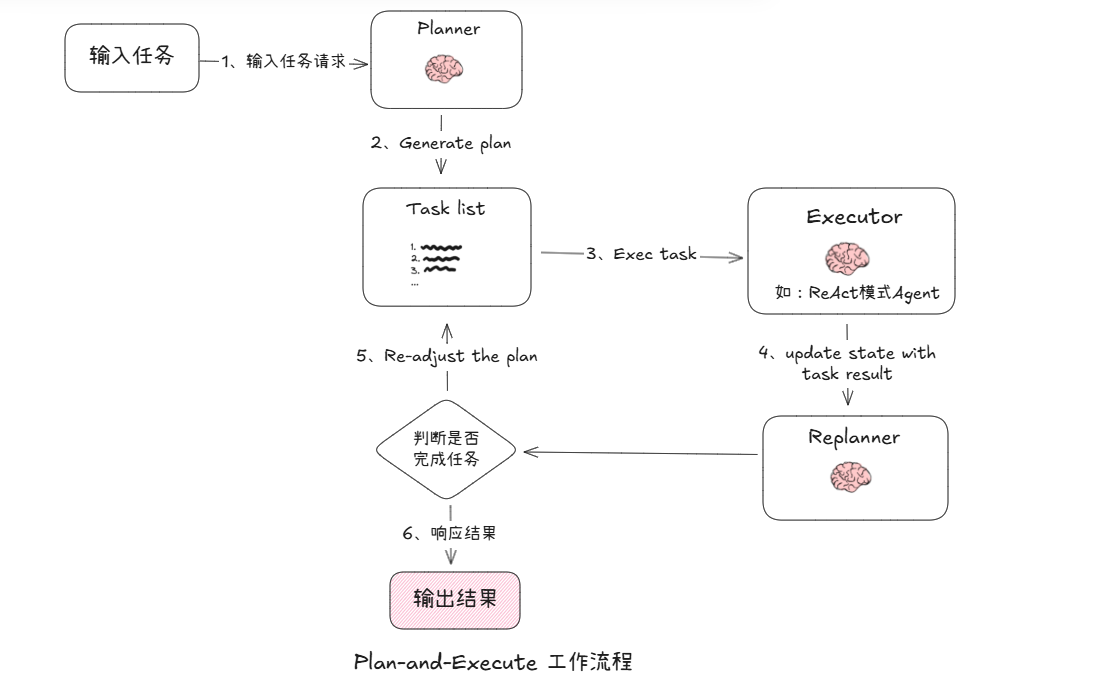
- 输入任务:接收来自用户用户或系统提交待处理的任务。
- Planner(规划器):接收任务后,调用模型(LLM)对任务进行深入分析,生成清晰的分步执行计划(即
Task list)。存储生成的计划列表,作为后续执行的 “行动指南”,让复杂任务变 “可落地步骤”。 - Executor(执行器):按任务列表逐个子任务执行,每次取出任务列表中的第一个任务进行处理,并将返回执行的结果传给
Replanner。 - Replanner(重规划器):接收执行结果后,结合任务目标进行评估执行偏差,判断是否已经完成任务,还是需要调整计划。若以完成任务,则生成最终响应;若未完成,则生成调整计划列表。
- 更新计划清单:更新
Replanner生成的调整计划列表。进入2-3循环。 - 输出结果:任务完成后,输出最终成果(如完整报告、问题解决方案 ),结束流程。
4. 与其它模式的对比
Plan-and-Execute 架构与类似框架ReAct、ReWOO的核心对比如下:
- ReAct:通过 “思考→行动→观察” 的循环来实现动态决策。智能体先对任务需求进行思考分析,做出下一步行动决策并执行,再观察行动的结果进行下一轮的思考分析,逐步逼近目标 。但本质是 “局部决策驱动”,每步仅聚焦单个行动选择,缺乏对任务全局的统筹规划,复杂场景下易出现路径冗余或目标偏移,且每次工具调用前均需触发 LLM 调用,Token 消耗与效率成本较高。
- ReWOO :ReWOO 是对 ReAct 框架的优化,主要是引入规划器,将核心组件拆分为三个独立模块:规划器、工作器和求解器。先使用规划器分解任务并制定相互依赖的计划(子任务)列表;再交给工作器依次执行;执行完成后由求解器整合结果。解决了 ReAct 中 “每次执行工具调用前,都需触发一次 LLM 调用以确定行动,导致 LLM 调用频次过高"的问题,从而显著降低 Token 消耗。但生成计划后,计划执行较为刚性,缺乏动态调整机制。若某子任务执行结果与预期偏差(如检索到的信息失效、工具调用失败),无法对原有计划进行调整,易导致 “一步错、步步错”的问题。
- Plan-and-Execute 框架:采用 “规划 - 执行 - 反馈 - 调整” 的闭环逻辑。与 ReWOO的关键区别,是新增了 Replan(重规划)机制,弥补了 ReWOO “计划生成后缺乏动态调整机制” 的局限。流程上,规划器先借助 LLM 完成任务全局拆解,生成完整分步计划 ;执行器按计划调用工具执行任务;重规划器根据执行反馈判断是否调整计划,若需调整则重新规划,确保任务朝着目标推进。由于可根据实时反馈优化计划,更适配复杂多变的任务场景。
6. 代码实现
6.1 架构设计
Plan-and-Solve 的架构由以下几个核心组件构成:
- 规划器 (Planner):负责将复杂任务拆解为可落地的多步骤执行计划,为后续行动明确路径。通常由具备强推理能力的大语言模型(LLM)承担。
- 执行器 (Executor):负责执行规划器生成的具体计划任务。执行器可以是另一个大语言模型,也可以是一个专门设计的 Agent,如 ReAct 模式的Agent,通过 “思考 - 行动 - 观察” 的循环,自主思考、决策下一步的行动、调用工具(如调用API,查询数据库、代码执行器)来完成计划任务。
- 重新规划器(replanner):接收执行器反馈的子任务结果,通过 LLM 评估 “实际结果是否符合计划预期”,若出现偏差(如数据缺失、工具调用失败、新信息出现),则触发重新规划,并更新计划列表。
- 状态管理(State):扮演 “记忆中枢”,负责跟踪任务的当前状态,包括当前计划、已执行的步骤及其结果、当前的响应等。状态管理器确保 Agent 在执行过程中能够保持上下文感知能力。
6.2 编写代码
6.2.1 前置准备
-
环境要求:
- Python 3.11+
- 安装依赖库:
pip install openai requests python-dotenv langchain_community langgraph langchain_openai langchain-tavily
-
基础配置:
-
设置模型调用API Key
创建
.env文件,配置模型 API访问密钥,这里使用千问模型,需配置QWEN_API_KEY及QWEN_BASE_URL。1 2 3 4 5# 千问模型接口访问key # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key QWEN_API_KEY="sk-*******" # 千问模型接口访问地址 QWEN_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1" -
搜索引擎 API 密钥(这里使用tavily)
.env文件中配置搜索引擎tavily API 密钥,Tavily国内需科学上网才能访问:1 2 3# tavily 搜索API KEY # 访问 https://tavily.com 注册并获取API Key,用户每月有1000次免费调用额度. TAVILY_API_KEY="tvly-ZuSNSW4CehsNizV****"
-
6.2.2 引入依赖包
引入相关依赖,读取.env文件中配置的参数转化为环境变量。
|
|
6.2.3 配置与常量(Config 类)
该类集中管理所有静态配置,便于维护。
|
|
6.2.4 定义状态
LangGraph 工作流的核心是状态(State)在节点间的流转,而 state 则定义了节点间传递的数据结构,主要包含三部分:
- 当前计划列表:用字符串列表记录待执行的步骤;
- 已执行步骤记录:用元组列表存储(包含步骤内容 + 执行结果);
- 基础信息:包括最终响应和原始输入数据。
|
|
6.2.5 LLM 与工具初始化(核心能力封装)
该部分负责定义智能体的 “大脑”(LLM)和 “手脚”(工具),是智能体具备 “思考” 和 “行动” 能力的基础。
(1)initialize_llm:初始化语言模型
|
|
- 环境变量管理:通过
os.getenv从.env文件读取密钥,避免硬编码(安全最佳实践)。 - 这里使用 LangChain 的
ChatOpenAI类来访问千问模型,可以替换为兼容 OpenAI 接口格式的其它模型。替换为其它模型,需要修改这里的api_key(模型API访问密钥)、base_url(模型API地址)、model(模型名称)参数。
(2)initialize_tools:初始化工具
|
|
这里默认只添加了网络搜索工具Tavily,可根据业务场景添加其它的工具。
6.2.6 定义规划器节点
规划器节点根据用户输入,生成完成任务的计划步骤列表。
|
|
PydanticOutputParser.get_format_instructions():生成 LLM 可理解的格式说明,指导LLM输出相应的响应格式(如 “输出应为 JSON,包含 steps 字段,类型为列表”),确保 LLM 输出合规。with_structured_output(Plan):LangChain 的便捷方法,替代手动解析 LLM 输出(无需自己写 JSON 解析逻辑)。
6.2.7 定义执行器节点
执行器节点从当前计划列表中,取出第一个任务进行执行,并记录执行结果。这里使用ReAct模式的智能体作为执行器。
|
|
agent_response["messages"][-1].content:React 智能体的输出存储在messages列表中,最后一条消息是最终执行结果。- 单步执行:每次只执行计划的第一步,后续通过 “重新规划” 决定下一步,避免步骤混乱。
6.2.8 定义重新规划节点
重新规划节点根据 “已执行步骤结果”,通过 LLM 评估下一步的操作:
- 直接返回答案:如果已经做完的步骤,已足够信息能得出用户要的结果,则直接生成响应答案给用户。
- 继续执行新计划:如果还未完成,则重新生成计划,并更新state中的计划列表。
|
|
6.2.9 定义路由节点
判断工作流是否结束,是 “继续执行” 还是 “终止”。
|
|
6.2.10 定义图(LangGraph 核心)
图定义工作流的 “节点连接关系”,即 “从哪里来,到哪里去”。
|
|
6.2.11 主程序(运行入口)
main函数是代码的执行入口,负责初始化环境、构建工作流。
|
|
6.2.12 完整代码
完整代码位于项目根目录下:cognitive_pattern/plan_and_solve/plan_and_execute.py
|
|
6.3 运行测试
执行以下命令,由于使用tavily搜索引擎,需要配置科学上网哦:
|
|
或者在IDE如pycharm中右键运行。
执行结果如下:
|
|
最后响应结果为:{'response': '2024年澳大利亚网球公开赛男子单打冠军扬尼克·辛纳的家乡是意大利的桑坎迪多(San Candido)。'}
6.4 结论
从设计角度看,Plan-and-Execute是对ReAct和ReWOO模式的进一步优化:
- 相比
ReAct,它的优势在于推理阶段就形成明确的长期规划,能指导执行路径,解决了ReAct缺乏对任务全局的统筹规划、复杂场景下易出现路径冗余或目标偏移的问题; - 相比
ReWOO,它新增eplanner(重规划器),实现了计划的动态调整机制,弥补了ReWOO一旦生成计划就无法灵活调整的缺陷 —— 避免了因某子任务执行结果偏离预期却无法修正,最终导致 “一步错、步步错” 的问题。
不过Plan-and-Execute存在一个明显局限:任务需按顺序执行,下一个任务必须等待上一个完成才能启动,总执行时间等同于所有任务耗时之和,效率较低。改进的方式是:可将任务的 “线性列表” 式结构,转化为有向无环图(DAG) 结构 —— 通过 DAG 明确任务间的依赖关系,让无依赖的任务实现并行执行,可大幅缩短总耗时。这种改进思路类似于LLM Compiler`设计模式的逻辑。
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/plan_and_solve
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/cognitive_pattern/plan_and_solve