主流开源 Rerank 模型解析与选型指南(2026 版)
在检索增强生成(RAG)场景中,Rerank(重排序)是决定检索精度的关键环节。核心作用是对向量检索、关键词检索等初步召回的候选文档进行精细排序,筛选出与查询最相关的结果,以提升检索精度。本文聚焦 6 款主流开源 Rerank 模型,从技术特性、性能表现、部署成本、适用场景等核心维度展开深度解析,结合 2025 年最新评测数据输出可落地的选型建议,助力开发者搭建高效的检索系统。
1 核心概念与模型速览
1.1 Rerank 核心价值
在检索增强生成(RAG)的流程中,初步召回阶段(如向量检索)追求“全”,核心是尽可能网罗所有潜在相关文档,避免遗漏有价值的信息,这一阶段的结果精度通常不高。进入 Rerank 阶段后,核心诉求转向 “准”:通过深度建模查询与文档的语义关联,精准捕捉二者间的匹配逻辑,修正初步召回的排序偏差。一款优秀的 Rerank 模型,能在不显著增加系统延迟的前提下,将 MRR、NDCG 等核心相关性指标提升 20%-50%,是平衡检索效率与结果精度的关键核心组件。
另外,Rerank 的核心价值还体现在 “降本增效” 上:一方面,通过精准筛选剔除无关文档,可大幅减少后续 LLM 推理的输入文本量,降低 Token 消耗与推理延迟;另一方面,能有效避免无关信息对 LLM 的干扰,帮助模型更聚焦核心需求,进而提升生成内容的准确性与相关性。
1.2 当前主流开源 Rerank 模型速览(2025-12 更新)
| 模型名称 | 研发机构 | 发布时间 | 参数量 | 上下文长度 | 授权协议 | 核心亮点 |
|---|---|---|---|---|---|---|
| Qwen3-Reranker-4B | 阿里通义 | 2025-06 | 4B | 32k | Apache 2.0 | MMTEB-R 评分 72.74(高精度),支持32K长文本,中英文均衡适配,适合企业级高精度RAG |
| mxbai-rerank-large-v2 | MixedBread | 2025-07 | 1.5B | 8k | Apache 2.0 | BEIR 18项任务零样本SOTA,完美适配德/英/西/法等多语言场景,泛化性强 |
| bge-reranker-v2-m3 | BAAI | 2024-03 | 567M | 8k | Apache 2.0 | 中文社区主流选择,量化后体积<200MB,中英文混合场景表现突出,部署成本低 |
| jina-reranker-v3 | Jina AI | 202510 | 0.6B | 默认8k | CC-BY-NC-4.0(商用需授权) | 支持100+语言,专为Agentic-RAG场景微调,listwise交叉交互机制,适配多轮检索决策 |
| ms-marco-MiniLM-L6-v2 | Microsoft | 2021 | 22M | 512 | MIT | 超轻量架构,CPU/边缘端部署首选,英文通用场景标杆模型,推理速度快、集成成本低 |
| ColBERT v2 | CMU/Stanford | 2021-12 | 110M | 原生512 | MIT | 预编码+后期交互架构,百万级文档低延迟重排,吞吐较传统模型提升10倍,适合大规模英文知识库,长文本需分块处理 |
2 主流Reranker模型评测
(一)Mixedbread Reranker模型评测
2025年,Mixedbread在官方博客中针对旗下rerank-v2系列模型开展系统性评测,测试覆盖英文、中文、多语言、工具检索、代码检索五大类基准测试场景,并与其它同类开源/闭源模型进行了性能对比:
原文链接:https://www.mixedbread.com/blog/mxbai-rerank-v2
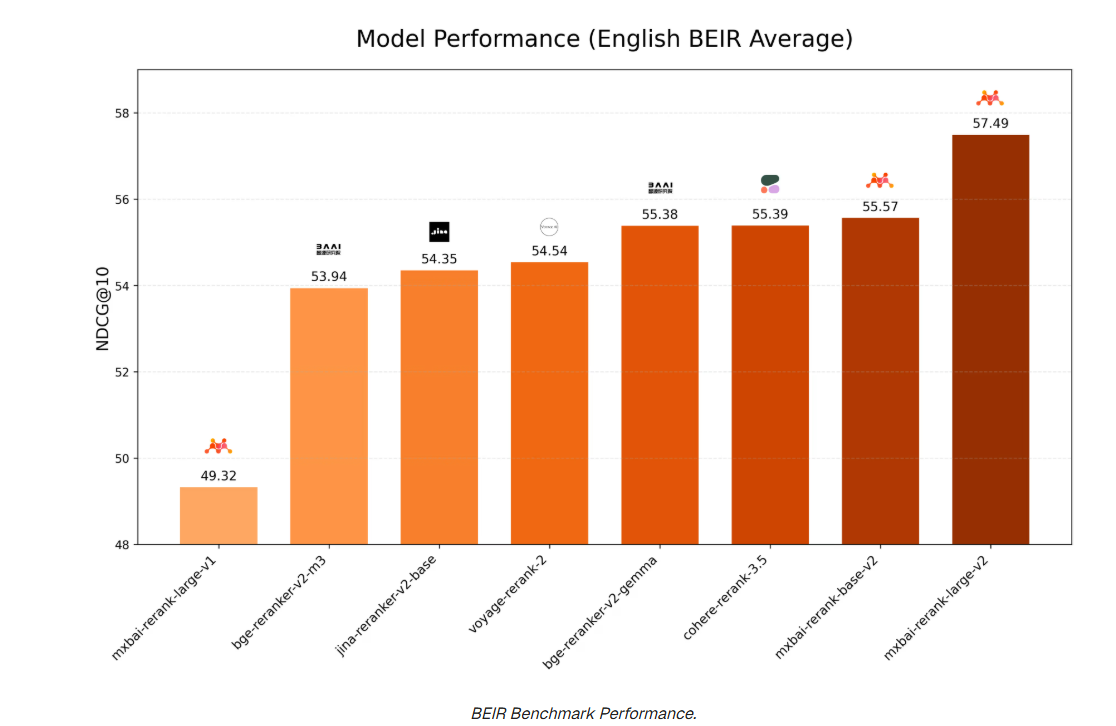
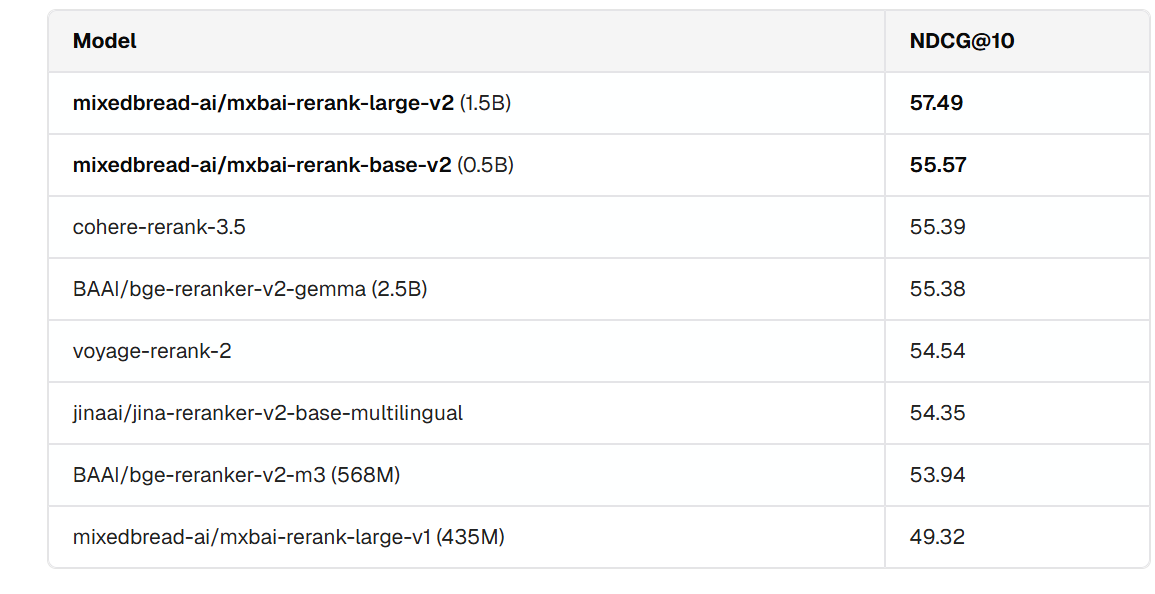
这里只列出英文、中文 BEIR 基准测试的表现。
英文 BEIR 基准测试性能
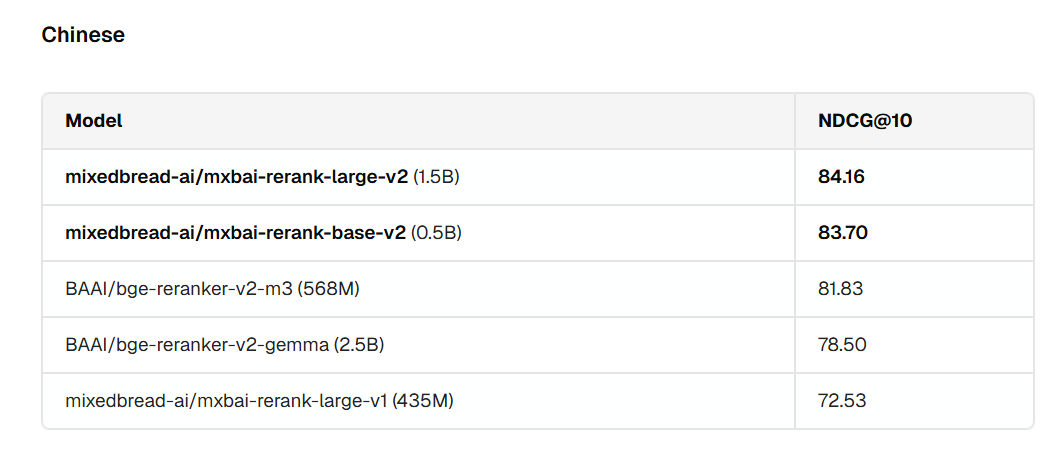
C-Pack(中文)检索基准测试表现
|
|
评测结果显示:mxbai-rerank-v2 在中文检索基准 C-Pack 中表现领先,15 亿参数版本以 84.16 分夺冠,5 亿参数版本获 83.70 分紧随其后;相较上一代,该模型得分提升超 11 分,检索准确率大幅突破,成为中文高精度检索场景的优选方案。
(二)阿里rerank系列模型评测
2025年6月,阿里发布Qwen3-Reranker-4B系列模型及对应的评测结果,相关信息可参考官方开源地址:
链接:https://github.com/dengcao/Qwen3-Reranker-4B
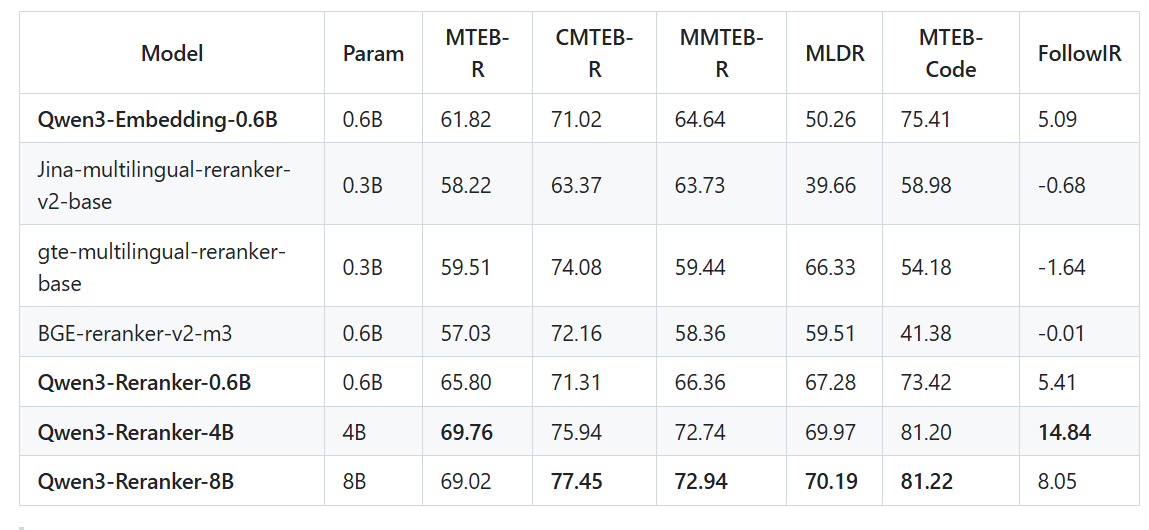
评测采用MTEB(英文,v2版)、MTEB(中文,v1版)、MMTEB及MTEB(代码领域)的检索任务子集,对应命名为MTEB-R、CMTEB-R、MMTEB-R与MTEB-Code。
所有评测分数均由阿里团队独立测试计算得出,测试基于稠密嵌入模型Qwen3-Embedding-0.6B(https://huggingface.co/Qwen/Qwen3-Embedding-0.6B)检索得到的前100条候选结果。
(三)Jina Reranker 模型评测
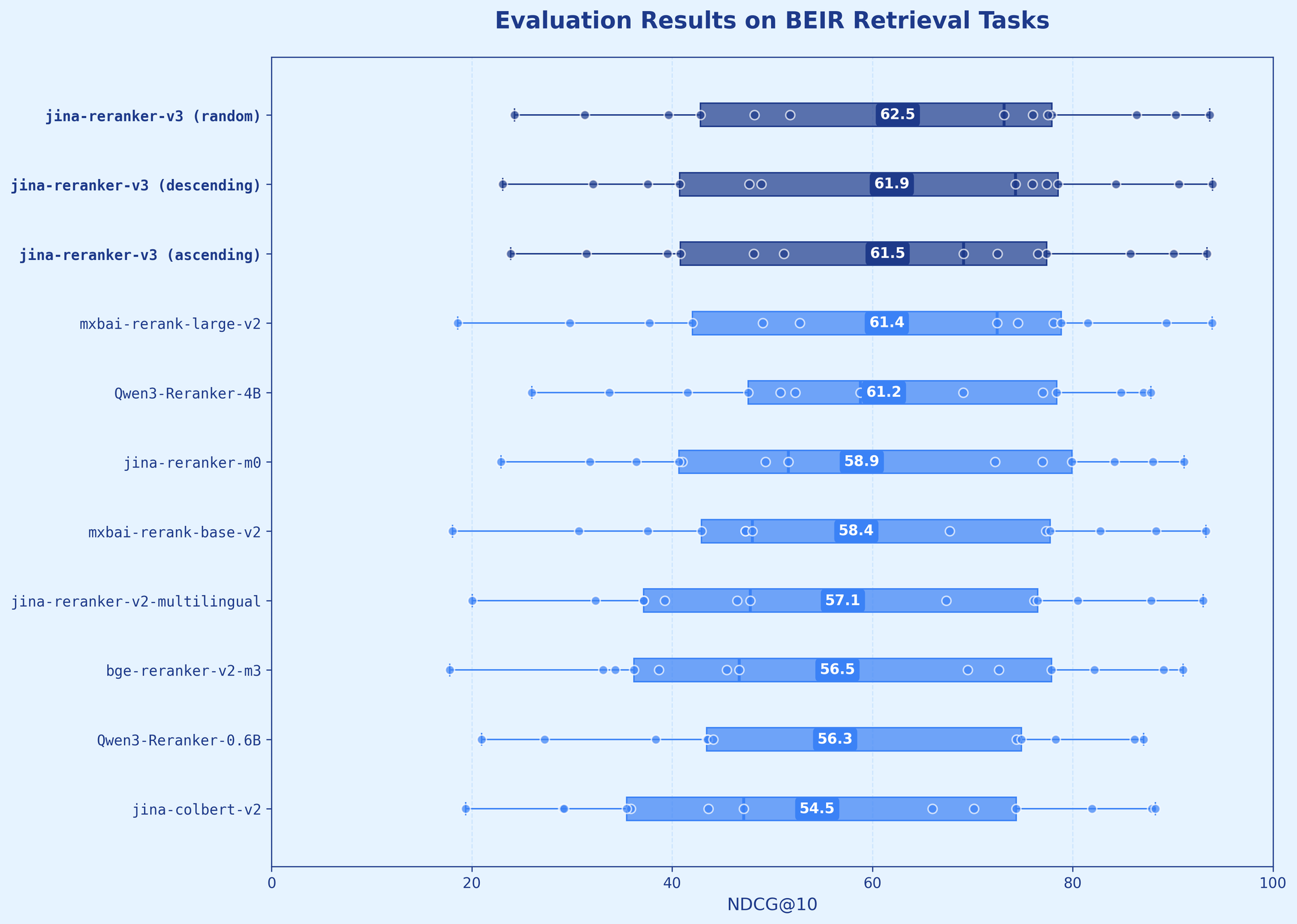
Jina 于2025年10月发布了jina-reranker-v3,这个新模型在 BEIR 上实现了 61.94 nDCG@10,优于 Qwen3-Reranker-4B,同时体积缩小了 6 倍。
链接:https://jina.ai/zh-CN/news/jina-reranker-v3-0-6b-listwise-reranker-for-sota-multilingual-retrieval/
展示了评测结果如下:
| Model | Size | BEIR | MIRACL | MKQA | CoIR |
|---|---|---|---|---|---|
| jina-reranker-v3 | 0.6B | 61.94 | 66.83 | 67.92 | 70.64 |
| jina-reranker-v2 | 0.3B | 57.06 | 63.65 | 67.90 | 56.14 |
| jina-reranker-m0 | 2.4B | 58.95 | 66.75 | 68.19 | 63.55 |
| bge-reranker-v2-m3 | 0.6B | 56.51 | 69.32 | 67.88 | 36.28 |
| mxbai-rerank-base-v2 | 0.5B | 58.40 | 55.32 | 64.24 | 65.71 |
| mxbai-rerank-large-v2 | 1.5B | 61.44 | 57.94 | 67.06 | 70.87 |
| Qwen3-Reranker-0.6B | 0.6B | 56.28 | 57.70 | 65.34 | 65.18 |
| Qwen3-Reranker-4B | 4.0B | 61.16 | 67.52 | 67.52 | 73.91 |
| jina-code-embeddings-0.5b | 0.5B | - | - | - | 73.94 |

在 BEIR 上衡量的英语检索性能,以 nDCG@10 为指标。所有分数都是我们基于来自 jina-embeddings-v3 作为第一阶段检索器的前 100 个结果进行的运行。我们评估了 jina-reranker-v3 的三个变体:按相关性得分降序排列的文档、升序排列的得分和随机排列。评估表明,v3 在不同的输入排序中保持相对稳定的性能,这表明强大的自注意力机制可以有效地处理文档,而不管其初始排列如何。
3 主流开源Rerank模型解析
本节从技术特性、性能与部署、优缺点、适用场景四个核心维度,对6款模型进行解析,为选型提供数据支撑。
3.1 Qwen3-Reranker-4B(阿里通义)
阿里通义Qwen3大模型生态的核心重排组件,4B参数实现“性能与效率的黄金平衡”,面向高精度 RAG、长文本检索及跨语言场景,是企业级部署的优选模型。
技术特性
- 架构:采用单塔 Cross-Encoder(交叉编码器)结构,将查询与候选文档拼接输入,通过动态交互特征计算相关性得分,相比传统双塔模型更精准捕捉细粒度语义关联;
- 长文本处理:支持32K tokens上下文,采用双块注意力机制保障长文档(如法律合同、科研论文)的语义连贯性,特别优化了专业领域长文本排序稳定性;
- 多阶段训练:① 先基于Qwen3-32B大模型生成1.5亿条弱监督query-doc数据对完成预训练,夯实基础语义匹配能力;② 在MS MARCO、BEIR、中文CLIR等12个权威高质量数据集上进行微调,针对性提升特定场景性能;③ 采用球面线性插值(slerp)技术合并多阶段训练检查点,进一步增强模型鲁棒性与泛化能力。
- 多语言支持:覆盖 119 种自然语言 + 30 种编程语言,跨语言检索平均误差较上一代降低 30 %,中文场景 MTEB-R 得分领先同类开源模型。
性能与部署
- 权威评测:MMTEB-R 72.74,MTEB-R多语言基准69.76分,代码检索任务得分突破81.0,远超同类模型;
- 硬件要求:FP16精度下需14GB显存(推荐A100/RTX4090),AWQ量化后显存降至8GB,精度损失<1%;
- 推理延迟:100文档排序延迟<100ms(A100),支持vLLM加速提升吞吐量;
- 授权协议:Apache 2.0,完全开源可商用,支持Hugging Face、ModelScope及GitHub获取权重。
优缺点
- 优点:综合性能顶尖,长文本/跨语言能力强,开源可商用,生态完善;
- 缺点:参数规模较大(4B),推理速度慢于轻量模型,低显存设备(如T4)部署受限。
适用场景
- 企业级RAG系统精排环节:适配金融、法律、医疗等行业的高精度问答场景,可与Qwen3-Embedding-4B组合构建“初检索+精排序”全流程RAG方案,提升企业知识库、智能客服的回答准确率,降低模型幻觉率。
- 专业领域长文本检索:适用于法律合同审查、科研论文检索、企业技术手册匹配等场景,能精准捕捉长文本中的关键语义信息,助力专业人员快速定位核心内容,提升工作效率。
- 多语言/跨境检索场景:可支撑跨国企业知识库构建、跨境电商商品搜索等需求,在西班牙语-英语、中文-俄语等跨语言匹配任务中表现优异,能显著提升小语种市场的检索准确率与用户体验。
- 代码检索与研发辅助:针对30种编程语言的代码片段检索优化,可应用于企业研发知识库、智能编码辅助工具(如通义灵码),帮助开发人员快速定位所需代码资源,提升研发效率。
3.2 mxbai-rerank-large-v2(MixedBread)
MixedBread 第二代重排模型的旗舰版本,包括 mxbai-rerank-base-v2(5 亿个参数)和 mxbai-rerank-large-v2(1.5B,15 亿个参数)。它们是基于 Qwen-2.5 架构的开源(Apache 2.0 许可证)交叉编码器。1.5B参数主打多语言零样本泛化,是BEIR基准18项任务的零样本SOTA,适合全球化应用及多语言检索场景。
技术特性
- 架构:DeBERTa-v3-large 优化,Cross-Encoder + 动态注意力,语义交互建模更精准;
- 强化学习训练:在初始训练的基础上融入了三阶段强化学习 (RL) 方法:引导强化提示优化(GRPO)+对比学习+偏好学习。让模型输出更清晰的相关性得分,精准区分文档优先级;
- 多语言适配:原生支持德、英、西、法等多语言,无需额外微调即可适配全球主流语言场景;
- 低集成成本:可直接对接Elasticsearch/OpenSearch等关键词搜索引擎,无需修改现有基础设施,一行代码即可提升检索相关性。
性能与部署
- 权威评测:BEIR平均NDCG@10 57.49,MR-TyDi多语言数据集29.79,零样本泛化能力行业领先;
- 硬件要求:推荐GPU部署(A10以上),单查询处理耗时0.89s(A100,NFC数据集),比同类大模型快8倍;
- 授权协议:Apache 2.0,开源可商用,支持Hugging Face/Transformers兼容,vLLM加速。
优缺点
- 优点:多语言零样本性能顶尖,集成成本低,商用友好;
- 缺点:1.5B参数推理速度慢于轻量模型(如bge-rerank-v2-m3),中文场景微调数据较少。
适用场景
- 全球化多语言检索:适配德/法/西/英等多语言文档库,无需针对单一语言微调即可实现多语种内容精准排序。
- 现有搜索引擎优化:为已部署Elasticsearch/OpenSearch的企业提供轻量升级方案,通过接入模型快速提升关键词检索的语义相关性,无需重构现有系统。
- 零样本跨语言迁移:适用于小语种地区电商商品检索、跨境客服知识库等场景,依托强大的零样本能力快速适配低资源语言市场,提升当地用户检索体验。。
3.3 bge-rerank-v2-m3(BAAI)
作为北京人工智能研究院(BAAI)FlagEmbedding项目的核心成员,主打“轻量化+中英文混合适配”,是中文社区最受欢迎的重排模型之一。核心定位为资源有限场景(低配置硬件、低成本部署)提供高效重排方案,兼顾中英文检索精度与部署效率。
技术特性
-
架构:基于 BERT 类优化的 Cross-Encoder,query-passage 拼接建模语义交互;
-
多语言优化:基于XLM-RoBERTa预训练,融合中英文海量语料微调,采用SentencePiece分词器适配非空格分隔语言,跨语言语义对齐能力强,尤其适配中英文混合场景;
-
高效训练:通过知识蒸馏将大模型知识迁移到567M参数模型,同时采用对比学习、多任务学习提升泛化性;
-
量化友好:支持FP16/INT8/INT4量化,量化后体积<200MB,可在低配置设备运行。
性能与部署
- 权威评测:中文C-MTEB排名前列,中英文混合场景MRR@10≈0.87,MTEB多语言基准表现优秀;
- 硬件要求:CPU(8核16G)可运行,GPU(T4)单卡QPS≈500(batch=32);
- 推理延迟:单样本GPU≈0.5ms,CPU≈10ms;
- 授权协议:Apache 2.0,开源可商用,FlagEmbedding库提供一键调用接口,支持ONNX/TensorRT加速。
优缺点
- 优点:中文表现突出,轻量化易部署,量化后成本极低;
- 缺点:英文精度不及 MixedBread,百万级候选排序效率低于ColBERT。
适用场景
-
中文为主的中小企业RAG系统:适配中文企业知识库、智能客服、内部文档检索等场景,在低成本硬件(如普通服务器、云服务器低配GPU)上即可部署,提升中文问答精度;
-
中英文混合办公场景:适用于有跨境业务的中小企业,可支撑中英文合同检索、双语产品手册匹配等需求,兼顾检索精度与部署成本;
-
边缘设备/低成本部署场景:如智能问答终端、中小企业轻量化检索工具等,INT4量化后可在低显存GPU或高性能CPU上运行,无需高额硬件投入。
3.4 jina-reranker-v3(Jina AI)
专为Agentic-RAG(智能代理驱动的RAG)设计的重排模型,主打多语言适配与listwise交叉交互,适合需要智能代理自主检索的场景。
技术特性
- 架构:Cross-Encoder,推理速度较 v1 提升 6 倍,吞吐量超 bge 15 倍;
- Agentic优化:针对Agentic-RAG场景专用微调,支持“检索-思考-再检索”的多轮交互逻辑,提升代理自主决策的检索精度;
- listwise交互:区别于传统pointwise(单文档评分),采用listwise策略建模候选文档间的相对相关性,排序更符合人类认知;
- 多语言覆盖:支持100+语言,可直接适配跨境电商、国际客服等全球化场景。
性能与部署
- 权威评测:MTEB多语言重排任务表现均衡,Agentic-RAG场景下相关性提升3%-5%;
- 硬件要求:轻量部署,GPU(T4)单卡QPS≈600(batch=32),CPU(8核16G)可运行;
- 授权协议:CC-BY-NC-4.0,非商用免费,商用需获取Jina AI官方授权;
- 生态支持:原生兼容LangChain、Haystack等RAG框架,支持Docker快速部署。
优缺点
- 优点:Agentic-RAG场景适配性强,多语言支持全面,推理速度快;
- 缺点:商用需授权,单语言精度略逊于Qwen3/mxbai-rerank-large-v2。
适用场景
-
Agentic-RAG智能代理系统:适配企业智能知识库代理、自主研发助手、智能决策系统等场景,支撑代理自主完成多轮检索与信息筛选,提升决策准确性;
-
多语言智能客服代理:适用于跨国企业的智能客服系统,通过智能代理自主检索多语言知识库,为全球用户提供精准问答服务,提升客服响应效率与质量;
2.5 ms-marco-MiniLM-L6-v2(Microsoft)
微软经典轻量重排模型,22M参数实现“极致轻量化”,是边缘端、CPU部署及高QPS场景的标杆,主打英文通用检索。
技术特性
- 架构精简:基于MiniLM-L6(6层Transformer)的Cross-Encoder,去除冗余参数,在保证基础精度的前提下最大化提升推理速度;
- 训练聚焦:仅基于MS MARCO英文检索数据集训练,专门优化英文通用场景的相关性判断;
- 生态兼容:原生支持所有主流检索框架(Haystack、LangChain、Pyserini),集成成本几乎为零。
性能与部署
- 权威评测:英文MTEB平均74.2,MS MARCO MRR@10≈0.885,英文通用场景性能稳定;中文无适配,MRR@10≈0.62(性能暴跌);
- 硬件要求:CPU(4核8G)即可高效运行,GPU单卡QPS≈2000+(batch=32);
- 推理延迟:单样本GPU≈0.2ms,CPU≈5ms,是所有模型中速度最快的;
- 授权协议:MIT协议,开源可商用,持续维护更新。
优缺点
- 优点:超轻量、推理最快,CPU部署友好,英文通用场景生态成熟;
- 缺点:仅支持英文,泛化性弱,垂直领域需额外微调。
适用场景
-
英文高并发检索场景:适配英文电商平台商品检索、英文资讯聚合平台、国际社交平台内容筛选等超高QPS场景,以极致低延迟保障用户检索体验;
-
边缘设备/CPU部署场景:如英文智能终端、嵌入式检索系统、无GPU资源的小型服务器等,在低配置硬件上即可稳定运行,实现轻量化英文检索功能;
2.6 ColBERT v2(CMU/Stanford)
ColBERT 采用后交互(Late-Interaction)架构,把“预编码 + 最后细粒度比对”做成两步,平衡速度、精度与规模。主打“百万级候选文档低延迟重排”,是搜索引擎、大规模知识库检索的核心选择。
技术特性
- 架构:ColBERT v2 延续了Late-Interaction 架构:离线索引阶段把文档编码成“token 级向量集合”,查询阶段同样把问句编码成向量集合,最后在线计算两集合的 MaxSim 加权和,既保留 Cross-Encoder 的细粒度精度,又具备 Bi-Encoder 的预编码效率,是工业级“百万级候选低延迟重排”的首选方案。
- 高效优化:引入向量压缩、动态维度选择技术,降低存储和计算成本,相比v1版本性能提升10%+;
- 长文本处理:原生上下文512token,长文本需分块处理,配合预编码机制可高效处理超长文档集合。
性能与部署
- 权威评测:英文MTEB平均78.7,MS MARCO MRR@10(10k候选)≈0.905,百万级候选排序效率超传统Cross-Encoder 10倍;
- 硬件要求:推荐A100/V100,支持分布式部署;100万文档向量约占用500G存储空间;
- 推理延迟:10k候选排序(GPU)≈0.5s,100k候选≈5s,百万候选≈30s;
- 生态支持:提供ColBERT Indexer工具链,集成Pyserini/Anserini等检索框架,开源免费(非商用友好)。
优缺点
- 优点:大规模候选排序效率极高,预编码降低检索延迟,精度接近高性能Cross-Encoder;
- 缺点:仅支持英文(中文适配难度高),部署复杂度高,存储成本高,小体量场景性价比低。
适用场景
- 大规模英文搜索引擎:适配商业英文搜索引擎、学术英文文献检索平台(如 arXiv 文献检索)等场景,处理百万级以上候选文档的高效重排,平衡检索速度与精度;
- 大规模英文知识库:适用于大型企业的英文内部知识库、全球英文技术文档库等场景,支持海量文档的快速精准检索,提升企业知识管理效率;原版的 ColBERT v2 仅支持英文,后续由 Jina AI 推出的 Jina-ColBERT-v2 已经扩展为多语言模型。
- 大型搜索引擎“二段重排”:召回 10 k → ColBERT 精排 200 → Cross-Encoder 终排 10,整体延迟 <500 ms。
4 开源Rerank模型选型
4.1 选型决策树(快速定位模型)
-
明确语言需求:是否以中文/中英文混合为主?
→ 是:优先从Qwen3-Reranker-4B、bge-reranker-v2-m3中选择;
→ 否:需支持英文/多语言?优先mxbai-rerank-large-v2、jina-rerank-v3;
-
平衡精度与速度:候选文档数量多少?
→ 候选数<50:选base版/轻量型Cross-Encoder(如bge-reranker-v2-m3) ;
→ 候选数50-200:选large版/高性能Cross-Encoder(如Qwen3-Reranker-4B、mxbai-rerank-large-v2);
→ 候选数>1k/百万级:选ColBERT v2(英文);
-
适配现有生态:现有技术栈适配需求?
→ 对接BGE嵌入模型:优先bge-reranker-v2-m3(生态无缝衔接) ;
→ 兼容sentence-transformers:可选所有Cross-Encoder模型(如mxbai-rerank-large-v2、ms-marco-MiniLM-L6-v2);
-
确认部署环境与授权:
→CPU/边缘端:选超轻量/量化模型(如:ms-marco-MiniLM-L6-v2);
→GPU环境:可选中大型高精度模型(如:Qwen3-Reranker-4B、mxbai-rerank-large-v2、jina-rerank-v3);
→商用场景:优先Apache 2.0/MIT协议模型;
4.2 核心选型维度决策表
说明:“对应优选模型”已结合2025年最新模型表现排序,优先推荐商用友好、生态成熟的方案。
| 选型维度 | 关键考量点 | 对应优选模型 | 补充说明 |
|---|---|---|---|
| 语言需求 | 中文为主/中英文混合 | 1. Qwen3-Reranker-4B;2. bge-reranker-v2-m3 | 前者精度更高,后者部署成本更低 |
| 英文为主/多语言(德/西/法等) | 1. mxbai-rerank-large-v2;2. jina-rerank-v3 | 前者零样本泛化性强,后者适配Agentic-RAG | |
| 仅英文 | ms-marco-MiniLM-L6-v2 | 超轻量,边缘端 / CPU 部署首选,英文通用场景标杆 | |
| 候选集规模 | 小体量(<1k) | 所有Cross-Encoder模型(优先轻量款:bge-reranker-v2-m3) | 轻量款可平衡速度与精度,降低资源占用 |
| 大体量(>1k/百万级) | 1. ColBERT v2(英文)、 Jina-ColBERT-v2 (多语言,包括中文)。 | 需配合高效召回策略(如Elasticsearch)使用 | |
| 性能优先级 | 精度优先(企业级RAG/专业领域) | 1. Qwen3-Reranker-4B;2. mxbai-rerank-large-v2 | 专业领域(金融/法律)建议补充少量领域数据微调 |
| 速度优先(高QPS/边缘端) | 1. ms-marco-MiniLM-L6-v2;2. bge-rerank-v2-m3(量化版) | 量化版可进一步提升速度,精度损失<5% | |
| 部署环境 | CPU/边缘端(低资源) | 1. ms-marco-MiniLM-L6-v2(仅英文); | 4核8G CPU可支撑QPS≈500+(单模型) |
| GPU(高资源) | 1. Qwen3-Reranker-4B;2. mxbai-rerank-large-v2;3.jina-rerank-v3 | 推荐16G+显存,支持批量推理提升吞吐量 | |
| 商业授权 | 商用无限制 | Qwen3-Reranker-4B、bge-rerank-v2-m3、mxbai-rerank-large-v2、ms-marco-MiniLM-L6-v2、ColBERT v2 | 均为Apache 2.0协议,企业商用无侵权风险 |
| 非商用/可接受授权 | jina-rerank-v3 | 商用需联系官方获取授权 |
4.3 典型场景化选型方案
以下典型场景化选型方案,覆盖金融、电商、客服、学术等主流领域,可直接参考复用。
场景1:中文企业级高精度RAG(如金融/法律文档检索)
-
首选方案:Qwen3-Reranker-4B
核心理由:中文语义理解精度领先(MMTEB-R 72.74),支持32K长文本(完美适配法律合同、金融年报等长文档),Apache 2.0协议商用无限制,4B参数在精度与部署成本间达到最优平衡。
-
备选方案:bge-rerank-v2-m3(量化版)+ 领域微调
核心理由:部署成本极低(量化后<200MB),中文社区生态成熟,配套微调工具链完善,少量领域标注数据(500-1000条)即可显著提升专业场景表现。
场景2:全球化跨境电商检索(多语言+高QPS)
-
首选方案:jina-rerank-v3
核心理由:支持100+语言(覆盖主流跨境市场),专为Agentic-RAG优化(适配电商多轮检索场景,如“先找商品→再找售后政策”)。
-
备选方案:mxbai-rerank-large-v2(量化版)
核心理由:多语言零样本性能顶尖(BEIR 18项任务SOTA),Apache 2.0协议商用友好,适合对检索精度要求更高的高客单价跨境场景(如奢侈品、工业用品)。
场景3:边缘端英文智能客服(CPU部署+高QPS)
-
唯一首选:ms-marco-MiniLM-L6-v2
核心理由:22M超轻量体积,4核8G CPU即可稳定运行,QPS可达1000+,满足边缘端(如门店智能终端、小型服务器)部署需求;英文通用场景精度稳定,客服常见问题(FAQ)检索准确率>90%。
场景4:百万级英文知识库检索(如学术论文库、技术文档库)
-
首选方案:ColBERT v2
核心理由:预编码+后交互架构,支持百万级文档低延迟重排,推理速度较传统Cross-Encoder提升10倍;精度接近高性能Cross-Encoder,学术论文相关性检索NDCG@10>0.85。
-
配套方案:Elasticsearch召回 + ColBERT v2重排
核心理由:通过Elasticsearch实现高效初步召回(召回率>95%),再由ColBERT v2进行精准重排,平衡召回全面性与排序精度,整体检索延迟<500ms。
场景5:Agentic-RAG智能代理(多轮检索+决策)
-
首选方案:jina-rerank-v3 核心理由:专为Agentic-RAG微调优化,listwise交叉交互机制可更好适配代理的多轮决策逻辑(如根据上一轮检索结果调整下一轮重排策略);多语言支持可适配全球化智能代理场景。
-
进阶方案: Qwen3-Embedding+jina-rerank-v3 核心理由:形成“高效召回+精准重排”黄金组合,Qwen3-Embedding提供高质量向量召回,jina-rerank-v3保障重排精度,多轮检索准确率较单一模型提升15%-20%。
4.4 选型避坑指南
-
避免跨语言硬适配:ms-marco-MiniLM-L6-v2、ColBERT v2无中文优化,强行处理中文会导致MRR(相关性评价核心指标)下降20%+;中文场景优先选原生中文优化模型。
-
大规模候选别用纯Cross-Encoder:mxbai-rerank-large-v2等纯Cross-Encoder在候选数>1k时,推理延迟呈指数级上升;建议采用“召回+重排”分层策略,或选用ColBERT v2等高效架构模型。
-
商用场景授权协议:jina-rerank-v3为CC-BY-NC-4.0协议,未经授权商用属于侵权;企业级项目优先选Apache 2.0协议的模型(如Qwen3-Reranker-4B、bge-rerank-v2-m3)。
-
不盲目追求大参数:4B参数的Qwen3-Reranker-4B虽精度高,但部署成本也高;若业务为通用中文场景(如通用FAQ检索),bge-rerank-v2-m3(567M)即可满足需求,成本仅为前者的1/5。
4.5 选型总结
6款主流开源Rerank模型各有侧重,选型核心逻辑是“对齐业务核心需求”,而非盲目追求性能指标。结合2025年最新技术趋势,给出以下核心选型建议:
- 追求「中文高精度+可商用」:首选Qwen3-Reranker-4B;
- 追求「多语言零样本+泛化性」:首选mxbai-rerank-large-v2;
- 追求「中文轻量化+低成本」:首选bge-rerank-v2-m3、Qwen3-Reranker-0.6B;
- 追求「Agentic-RAG+多语言」:首选jina-rerank-v3;
- 追求「英文边缘端+高QPS」:首选ms-marco-MiniLM-L6-v2;
- 追求「百万级英文候选+高效」:首选ColBERT v2。
落地建议:模型选定后,基于小批量真实业务数据开展验证测试,重点关注两大核心相关性指标 ——MRR@10(衡量首条正确结果的排序优先级)、NDCG@10(衡量前 10 条结果的整体排序质量);若业务场景特殊(如专业领域、小众语言),可通过少量领域数据微调进一步提升性能,确保模型真正适配业务需求。
5 开源Rerank模型使用示例代码
5.1 下载/加载模型
国内下载模型最主流的两个渠道 Hugging Face Hub和阿里云的 ModelScope(魔搭)。以下分别详细说明从两个平台下载 / 加载模型的完整流程,包括「自动下载」「手动下载」两种核心方式。
一、从 Hugging Face 下载 / 加载模型
Hugging Face 是全球最大的开源模型托管平台,国内需通过镜像加速解决网络问题,核心分「自动加载(推荐)」和「手动下载」两种方式:
方式 1:自动加载(配置镜像后自动下载)
适合希望自动下载模型的场景,核心是通过 HF_ENDPOINT 环境变量指定国内镜像源。
-
安装依赖
1pip install sentence-transformers transformers torch huggingface-hub -U -
配置国内镜像(关键)
国内无法直接访问
huggingface网站,可配置国内镜像或代理的方式访问,推荐国内镜像方式,只需配置镜像地址即可。-
临时生效(终端执行):
1 2 3 4 5 6# Linux/Mac export HF_ENDPOINT=https://hf-mirror.com # Windows CMD set HF_ENDPOINT=https://hf-mirror.com # Windows PowerShell $env:HF_ENDPOINT="https://hf-mirror.com" -
永久生效(推荐):
-
Linux/Mac:编辑
~/.bashrc或~/.zshrc,添加export HF_ENDPOINT=https://hf-mirror.com,执行source ~/.bashrc生效;示例:
1 2echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc source ~/.bashrc -
Windows:系统环境变量中新增
HF_ENDPOINT=https://hf-mirror.com(此电脑→属性→高级系统设置→环境变量)。
-
-
-
代码自动下载并加载
1 2 3 4 5 6 7 8 9 10 11 12import torch from sentence_transformers import CrossEncoder # 首次运行会从镜像源自动下载模型到本地缓存(默认路径:~/.cache/huggingface/hub/) # 后续运行直接读取缓存,无需重复下载 model = CrossEncoder( "BAAI/bge-reranker-v2-m3", device="cuda" if torch.cuda.is_available() else "cpu" ) # 测试使用 scores = model.predict([("人工智能", "大模型应用场景"), ("人工智能", "建筑工程设计")]) print(scores)
方式 2:手动下载(无网络限制,适合离线场景)
若镜像自动加载失败,可手动下载模型文件到本地,再加载。
-
下载模型文件
方式 1:通过 Hugging Face 镜像站 下载文件,核心文件包括:
核心文件 作用 pytorch_model.bin或model.safetensors模型权重(核心) config.json模型配置 tokenizer.json分词器配置 tokenizer_config.json分词器参数 vocab.txt词表文件 方式 2:用
huggingface-hub工具批量下载(需先安装:pip install huggingface-hub):1 2 3 4 5# 指定镜像源下载到本地目录(如 ./bge-reranker-v2-m3) huggingface-cli download \ --resume-download BAAI/bge-reranker-v2-m3 \ --local-dir ./bge-reranker-v2-m3 \ --endpoint-url https://hf-mirror.com下载完成后,本地目录会包含模型所有核心文件(
pytorch_model.bin、config.json、tokenizer.json等)。 -
加载本地模型
1 2 3 4 5 6 7 8 9 10 11import torch from sentence_transformers import CrossEncoder # 直接指定本地模型路径,无需联网 model = CrossEncoder( "./bge-reranker-v2-m3", # 替换为你的本地路径 device="cuda" if torch.cuda.is_available() else "cpu" ) scores = model.predict([("人工智能", "大模型应用场景"), ("人工智能", "建筑工程设计")]) print(scores)
二、 从 ModelScope(魔搭)下载 / 加载模型
ModelScope 是阿里云推出的国内开源模型平台,访问无需外网,天然适配国内环境。
方式 1:自动加载(一键下载)
适合直接通过 ModelScope 接口下载并加载,无需额外配置。
-
步骤 1:安装依赖
1pip install modelscope sentence-transformers torch -U -
步骤 2:代码自动下载并加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17import torch from modelscope.hub.snapshot_download import snapshot_download from sentence_transformers import CrossEncoder # 步骤1:从ModelScope下载模型到本地缓存(默认路径:~/.cache/modelscope/hub/) # 首次运行下载,后续直接读取缓存 model_dir = snapshot_download("BAAI/bge-reranker-v2-m3") # 步骤2:加载模型(与Hugging Face加载方式完全一致) model = CrossEncoder( model_dir, device="cuda" if torch.cuda.is_available() else "cpu" ) # 测试使用 scores = model.predict([("人工智能", "大模型应用场景"), ("人工智能", "建筑工程设计")]) print(scores)
方式 2:手动下载
若需将模型下载到指定目录(如服务器特定路径),可手动指定下载路径。
-
步骤 1:手动下载模型文件
方式 1:通过 魔塔平台 下载全部文件(核心文件包括:
pytorch_model.bin 或 model.safetensors、config.json、tokenizer.json、tokenizer_config.json、vocab.txt);方式 2:通过终端命令下载(需安装
modelscope):1modelscope download --model BAAI/bge-reranker-v2-m3 --local_dir ./modelscope_bge_reranker -
步骤 2:加载本地模型
1 2 3 4 5 6 7 8 9 10 11 12import torch from sentence_transformers import CrossEncoder # 直接指定ModelScope下载的本地路径 model = CrossEncoder( "./modelscope_bge_reranker", device="cuda" if torch.cuda.is_available() else "cpu" ) # 测试使用 scores = model.predict([("人工智能", "大模型应用场景"), ("人工智能", "建筑工程设计")]) print(scores)
5.2 开源 Rerank 模型使用示例代码
以下提供 6 款主流 Rerank 模型的示例使用代码,代码基于 Python 3.9+。
通用前置依赖安装:
|
|
一. Qwen3-Reranker-4B示例代码(中文高精度 + 可商用)
|
|
运行结果如下:

二. mxbai-rerank-large-v2示例代码(多语言零样本 + 泛化性)
|
|
执行结果如下:

|
|
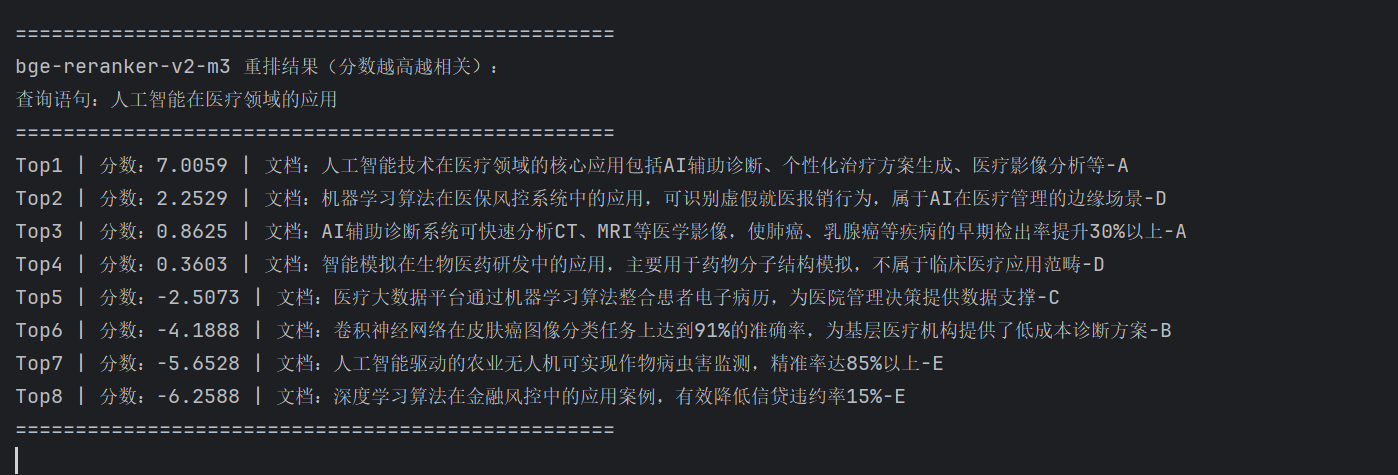
三. bge-reranker-v2-m3示例代码(中文轻量化 + 低成本)
|
|
执行结果如下:
|
|
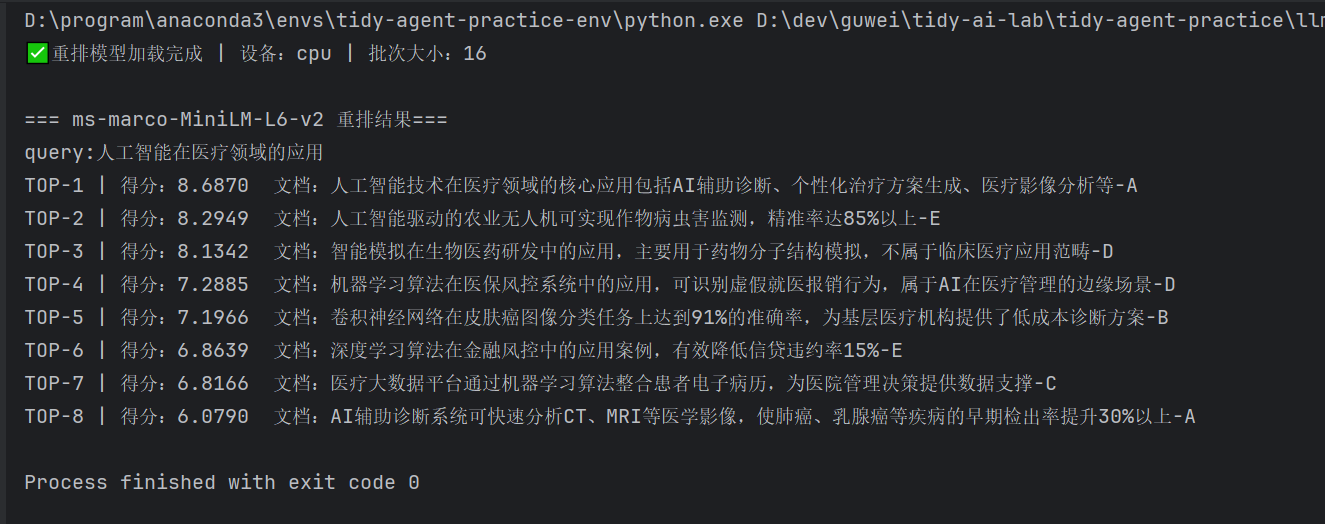
四. ms-marco-MiniLM-L6-v2示例代码(英文边缘端 + 高 QPS)
|
|
执行结果如下:
|
|
五. jina-rerank-v3示例代码(Agentic-RAG + 多语言)
|
|
执行结果如下:
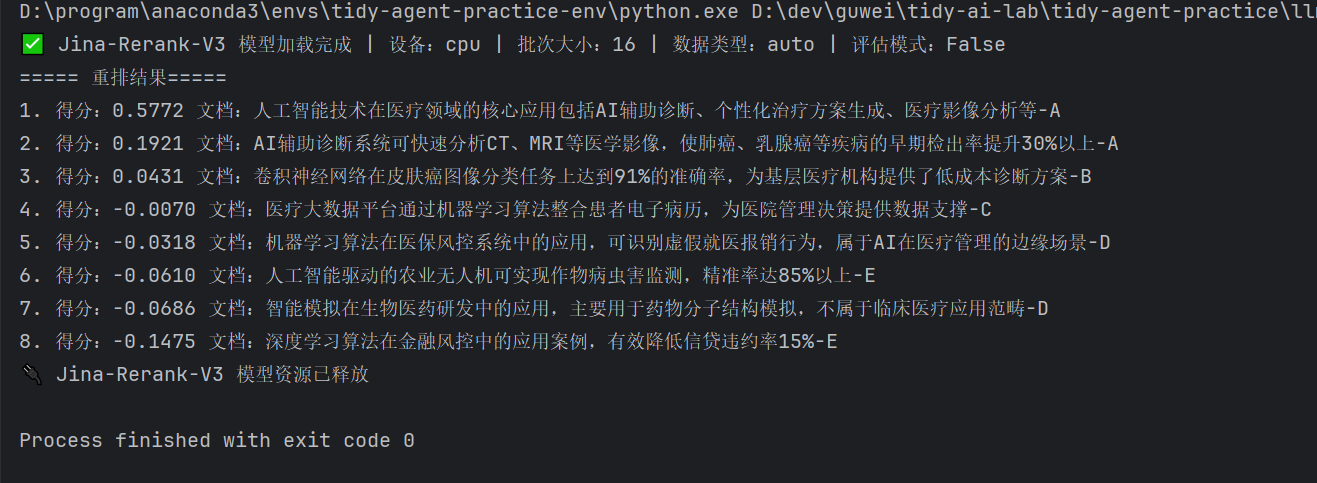
从执行结果可以看出jinaai/jina-rerank-v3模型对中文的reranker效果非常的好,基本上是标准答案。
六. ColBERT v2示例代码(百万级英文候选 + 高效)
|
|
执行结果:
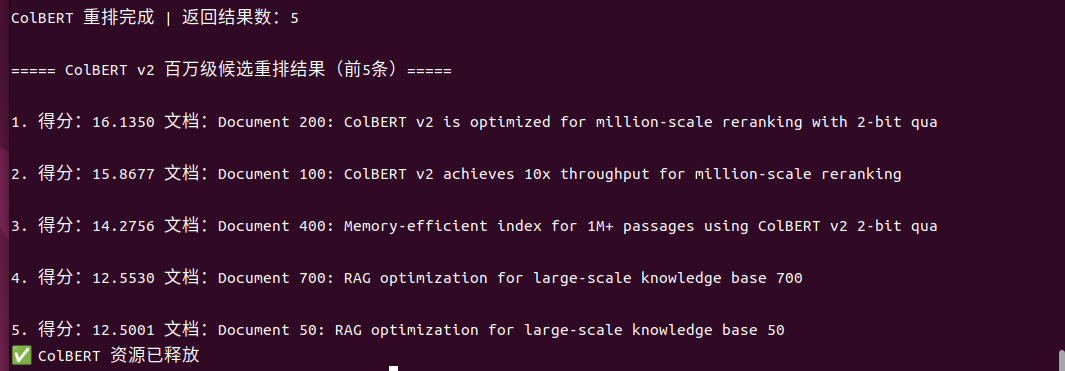
成功快速检索到了前3条高相关文档。
相关问题
执行过程中,ColBERT Windows 环境 C++ 扩展编译报错问题
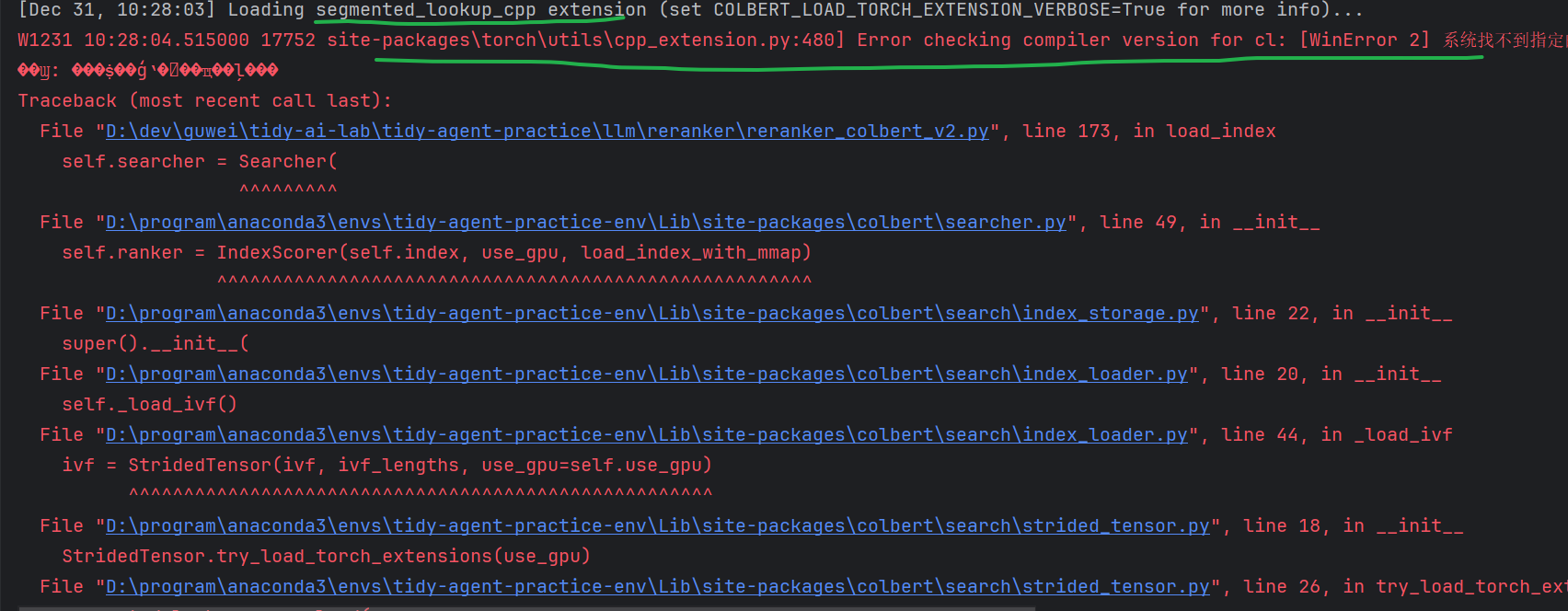
问题现象
ColBERT 框架默认依赖自研的 C++ 扩展实现高性能量化 / 检索,但在 Windows 系统下运行时,易触发编译器相关报错,核心错误信息:
|
|
根因说明
该报错本质是 Windows 系统缺少 ColBERT C++ 扩展编译所需的 MSVC 编译器环境,且 ColBERT 官方对 Windows 原生环境的兼容性支持有限。
推荐解决方案
- 最优方案:直接在 Linux 环境(如 Ubuntu 20.04+/CentOS 8+)中部署和使用 ColBERT,完全规避跨平台编译兼容问题;
- Windows 兼容方案:在 Windows 系统中启用 WSL2,WSL2 提供与原生 Linux 一致的运行环境,能正常编译并运行 ColBERT 的 C++ 扩展。
源码地址
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/llm/reranker
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/llm/reranker